









Você ainda tem a impressão de que geração de imagem por texto é apenas Nano Banana?
Mas filho, os tempos mudaram novamente.

@johnAGI168 https://x.com/johnAGI168/status/2044781168151724067

@0115hippo https://x.com/0115hippo/status/2044722124611539160
No início de abril, três modelos de imagem anônimos apareceram na plataforma de avaliação LM Arena, com os códigos maskingtape-alpha, packingtape-alpha e gaffertape-alpha. Eles desapareceram algumas horas depois.
A OpenAI ainda não anunciou oficialmente este modelo, mas, com base nos metadados retornados pela API e nos registros de testes realizados pelos usuários, ele já possui um nome amplamente aceito: GPT Image 2.

Screenshots não podem mais ser usados como evidência
Nos últimos anos, uma das principais limitações dos modelos de geração de imagens baseados em IA foi o texto nas imagens. Na era do DALL-E 3, pedir para ele escrever "Hello" na imagem podia resultar em "Hellp" ou até "Hl10", com letras cambaleantes, como se estivessem bêbadas. O GPT Image 1 melhorou muito, conseguindo lidar com rótulos simples em inglês. Já no GPT Image 1.5, a precisão na renderização de texto em inglês chegou perto de 95%, mas ainda apresenta deficiências claras em sistemas não latinos, como chinês, japonês e coreano.
Mas as imagens vazadas do GPT Image 2 alteraram essa impressão.

@MrLarus https://x.com/MrLarus/status/2044824800909054181
@akokoi1 https://x.com/akokoi1/status/2044789531615056175
O texto na imagem deve ser exatamente o que é. O chinês é claro, com formas de caracteres precisas e traços completos. Alguém testou gerar uma imagem no estilo de um cartão de identidade, com nome, endereço e número do documento renderizados corretamente, layout organizado, parecendo à primeira vista uma foto de documento real.

É uma ótima notícia. O avanço na renderização de texto significa que a geração de infográficos, cartazes, embalagens de produtos e gráficos com layout complexo tornou-se mais confiável.
Mas toda moeda tem dois lados. Um modelo capaz de gerar imagens de documentos falsificados de forma convincente e renderizar com precisão capturas de tela de interfaces torna cada vez mais suspeita a ideia de que "capturas de tela podem servir como evidência".
Em comparação, essa é também a diferença central entre a série GPT Image e outros modelos. O Midjourney ainda não conseguiu avançar na renderização de texto, e a série Stable Diffusion também enfrenta os mesmos problemas antigos. De acordo com os resultados vazados do teste Arena, o GPT Image 2 supera o Midjourney em quatro dimensões: renderização de texto, seguimento de instruções, realismo fotográfico e conhecimento do mundo; as vantagens do Midjourney permanecem principalmente no estilo artístico e no controle estético.

Ele realmente sabe como é o mundo?
Um tester pediu ao modelo para gerar uma página de preços fictícia do GPT-8, e a imagem resultante tinha um layout no estilo oficial da OpenAI, com botões e fontes que pareciam ser capturados de uma interface real, além de uma hierarquia lógica correta na tabela de preços.
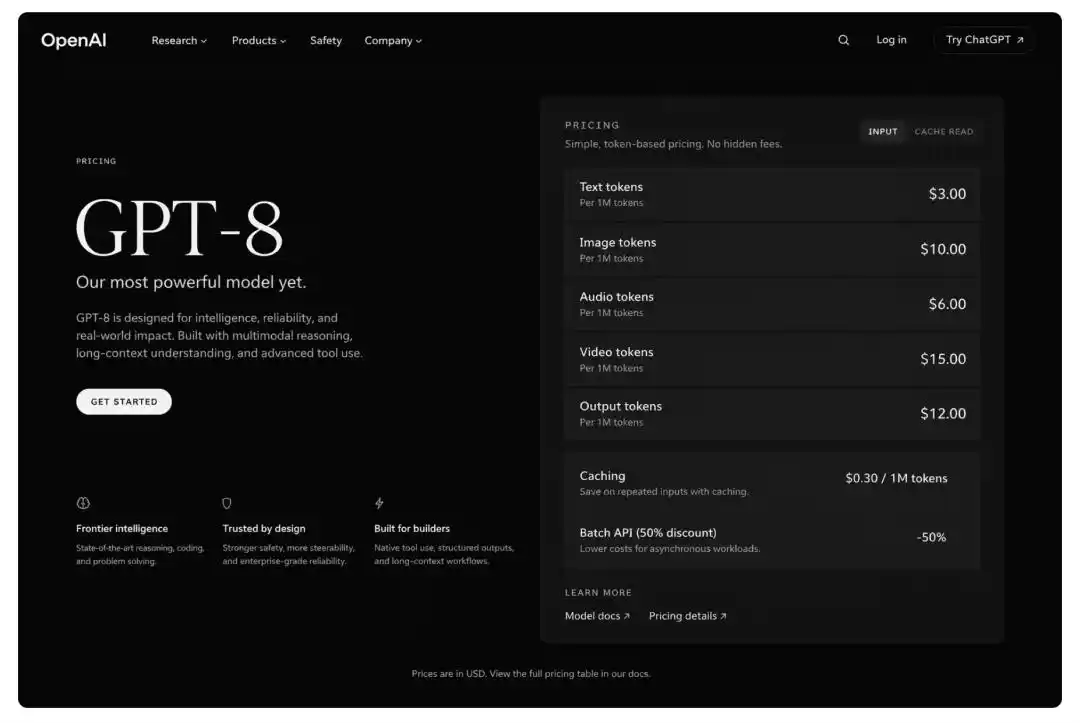
O GPT Image 2 pode gerar imagens extremamente semelhantes a interfaces de software reais, incluindo janelas de navegador, interfaces de aplicativos móveis e gráficos de visualização de dados, com fidelidade incomparável em relação à geração anterior.
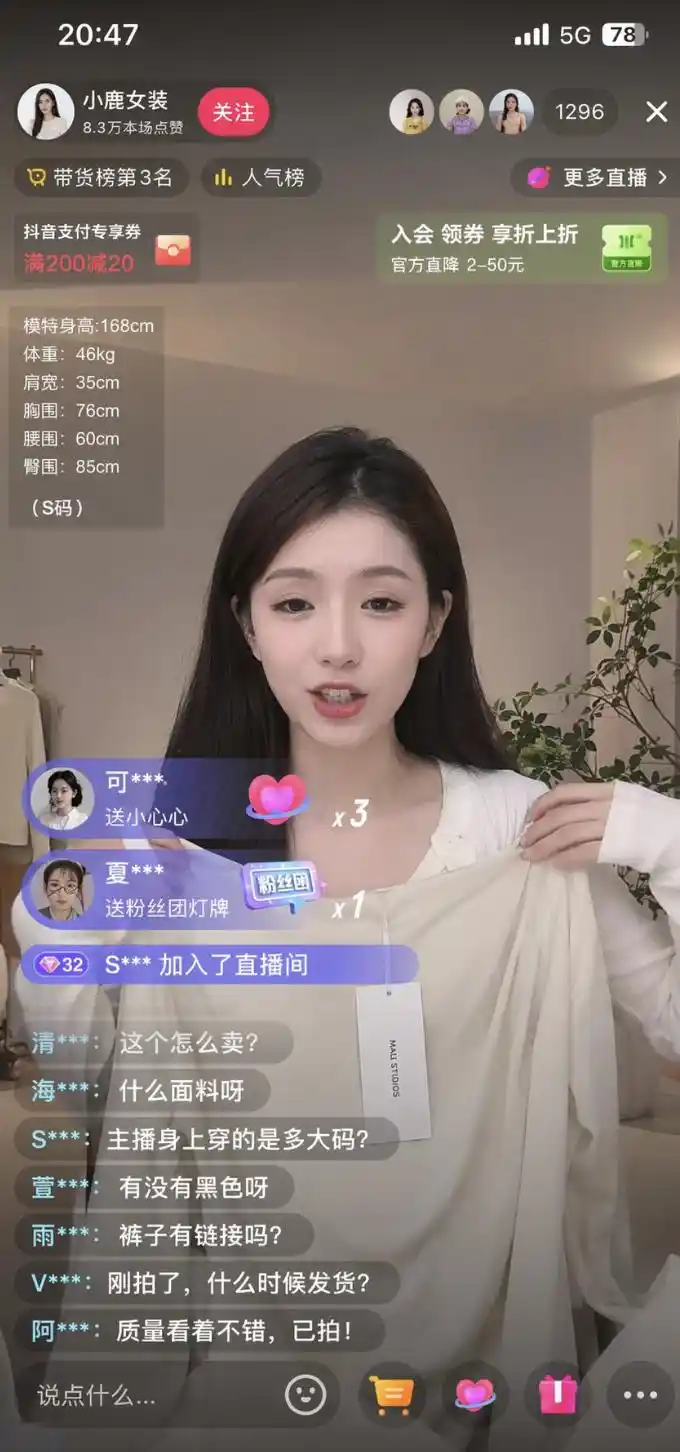
@johnAGI168 https://x.com/johnAGI168/status/2044781168151724067
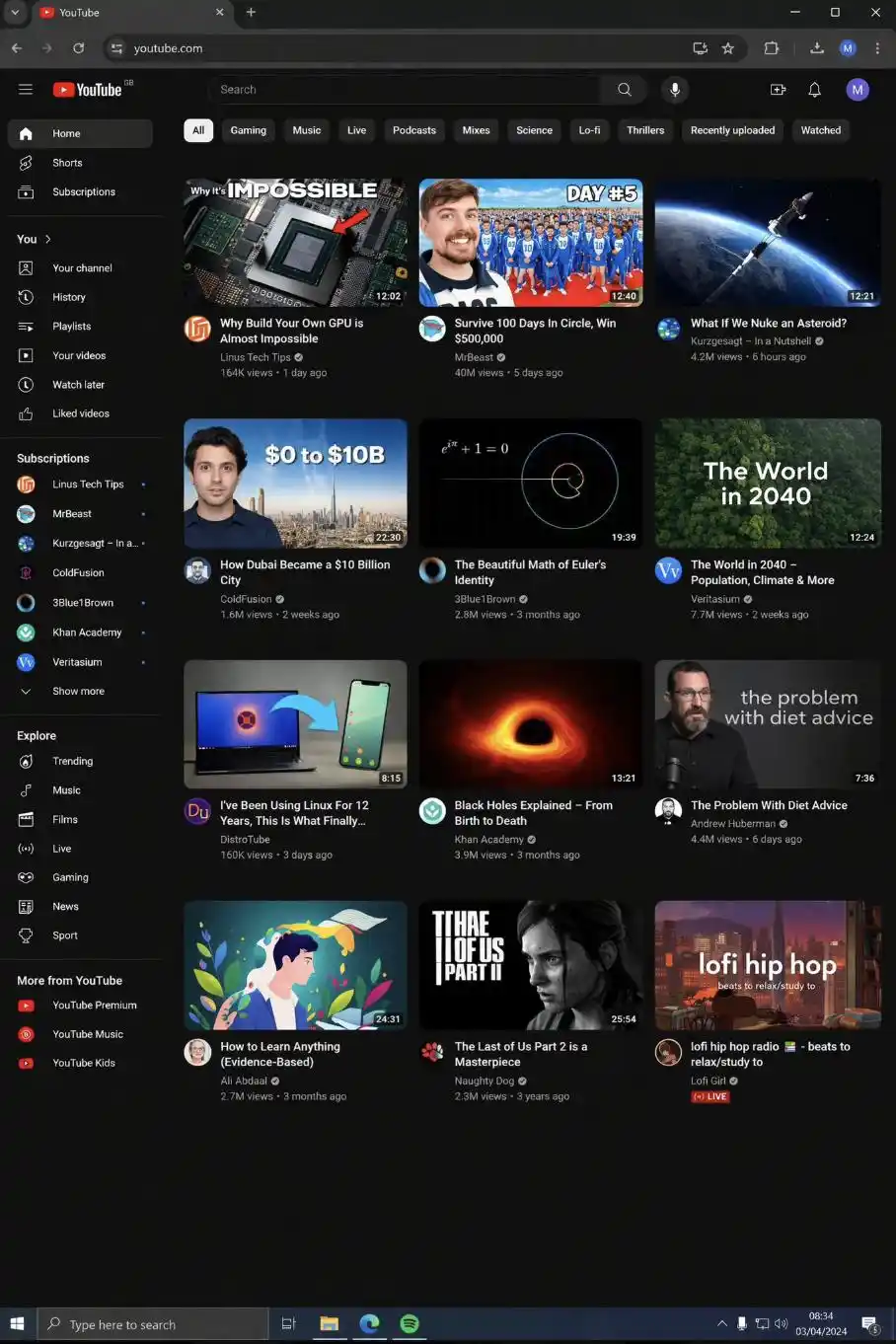
@levelsio https://x.com/levelsio/status/2040333489476681758
Isso trará algumas aplicações práticas muito interessantes. Quando designers criam protótipos de produtos, não precisam mais abrir primeiro o Figma para desenhar uma série de estruturas; basta descrever por texto a interface desejada, e o resultado será uma imagem de referência pronta para discussão com a equipe. Ao preparar apresentações para investidores, é possível exibir um “print do produto” sem precisar esperar os engenheiros escreverem o código. Ao redigir documentos, os exemplos de interfaces para ilustração podem ser gerados diretamente, sem precisar ficar olhando para uma página em branco tentando encontrar onde obter um print.
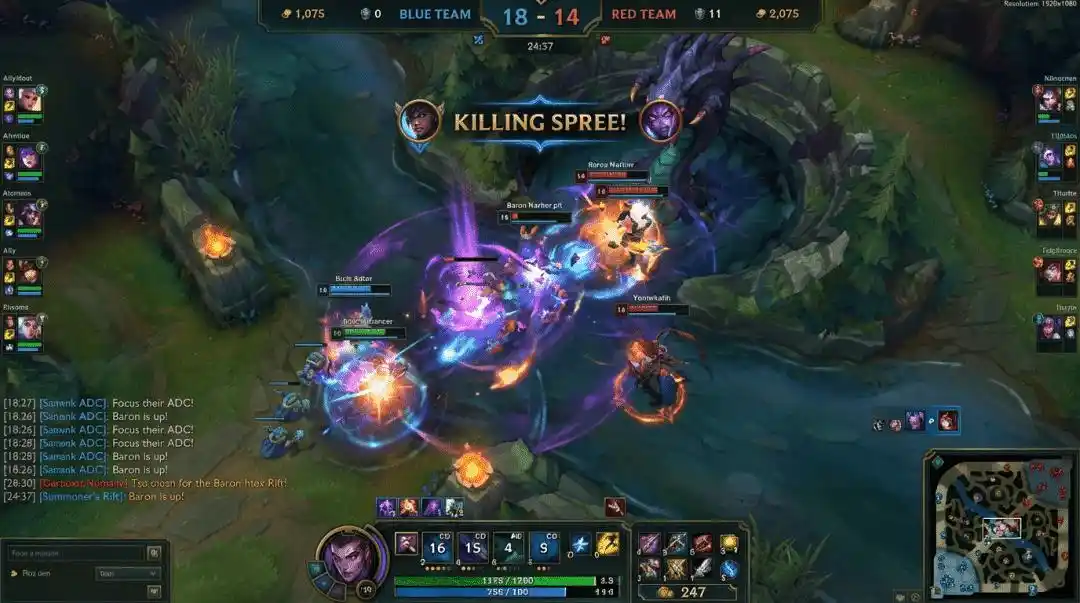

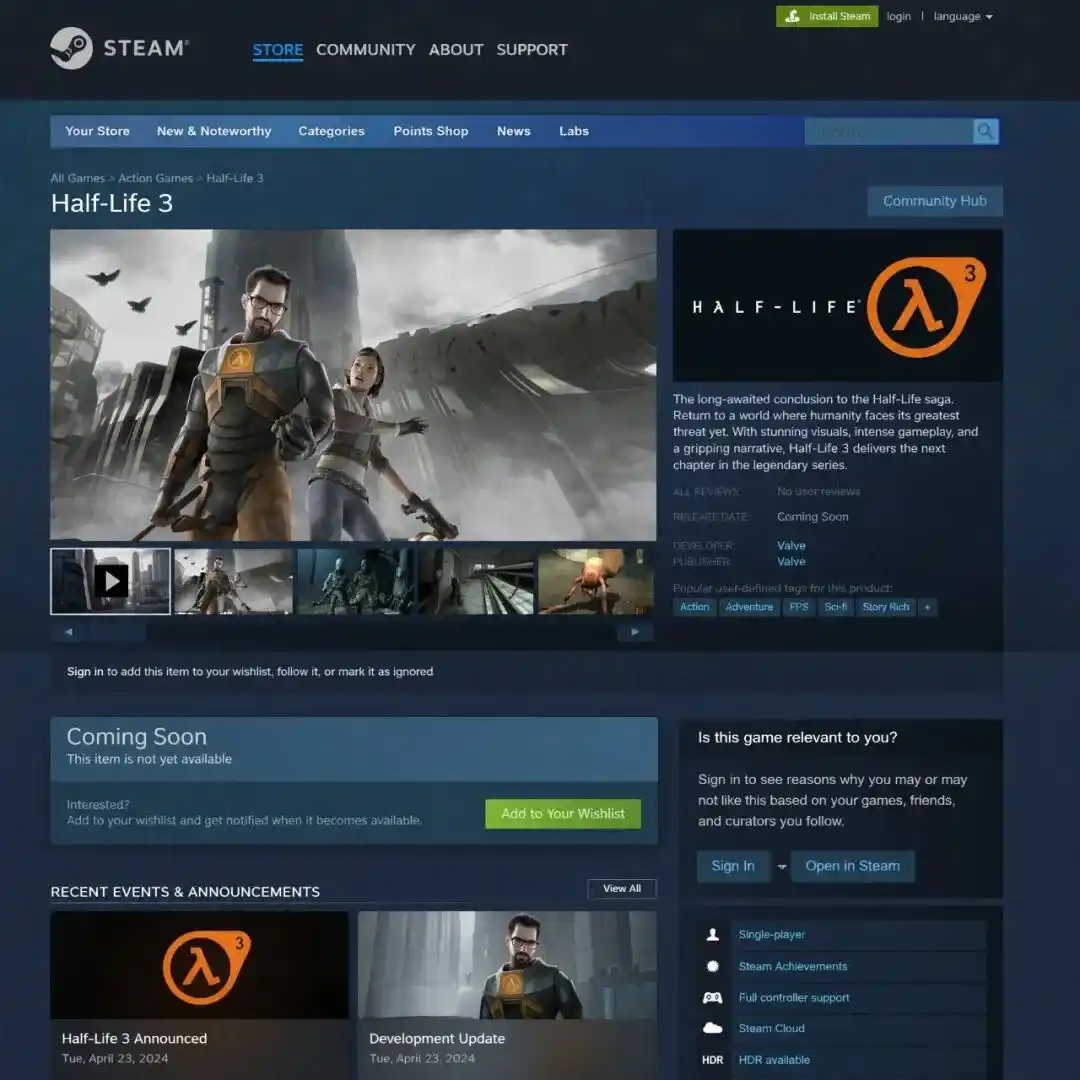
@marmaduke091 https://x.com/marmaduke091/status/2040338311873515597
Esse negócio de gerar imagens já não é mais apenas "gerar imagens"
A OpenAI anunciou que o DALL-E 2 e o DALL-E 3 serão descontinuados oficialmente em 12 de maio de 2026. O DALL-E 3 do Azure OpenAI já foi aposentado antecipadamente em fevereiro.
DALL-E foi o ponto de entrada de muitas pessoas para a geração de imagens por IA, e apenas alguns anos se passaram desde aqueles primeiros trabalhos borrosos até hoje.
Ao mesmo tempo, o Google, que apenas no início de 2026 estabeleceu sua posição na indústria com o Nano Banana Pro, pode sentir pressão. Relatórios de testes iniciais indicam que o GPT Image 2 superou o Nano Banana Pro simultaneamente em três dimensões: realismo, renderização de texto e conhecimento do mundo — uma vitória triplicada pouco comum.
Para criadores, os sentimentos são complexos. Ilustradores, designers gráficos e fotógrafos já não estão enfrentando esse tema pela primeira vez. Desde o lançamento do GPT Image 1, o número de vagas de design freelance diminuiu cerca de 18%. A IA realmente substituiu, em certos cenários, a decisão de “vou contratar alguém para fazer isso”, mas também está criando novas formas de trabalho, permitindo que uma única pessoa faça mais coisas.
A velocidade de evolução dos modelos de geração de imagens já não deixa muito tempo para adaptação. O GPT Image 1 passou da versão 1 para a 1.5 em apenas alguns meses. Da 1.5 para a 2, cerca de seis meses. Cada geração resolve as principais limitações da anterior e abre novas possibilidades.
O GPT Image 2 ainda está em fase de teste A/B, e alguns usuários do ChatGPT já receberam acesso aleatório. A janela de lançamento oficial é amplamente prevista para ocorrer em maio, por volta da aposentadoria do DALL-E. Para experimentar antecipadamente, atualmente é possível tentar sorte na plataforma de avaliação LM Arena.

Endereço de teste: https://arena.ai
Com base no feedback da comunidade e nas vantagens conhecidas deste modelo, o seguinte modelo de prompt pode maximizar suas chances de sucesso:
Dica de UI/ screenshot: Uma captura de tela fotorrealista de um aplicativo bancário no celular, mostrando claramente o histórico de transações, com data, valor e nome do comerciante legíveis. Tela do iPhone 16, segurando naturalmente o celular, com fundo de cafeteria.
Etiqueta do produto: foto realista de uma garrafa de cerveja artesanal, com detalhes nítidos da etiqueta, mostrando o nome da cervejaria «Oakridge Brewing Co.», teor alcoólico de 6,8%, logotipo de montanhas e lista de ingredientes. Iluminação em estúdio, fundo branco.
Dica de identificação: Uma foto da paisagem urbana de uma rua noturna em Tóquio, mostrando várias placas de néon bilíngues em japonês e inglês, incluindo a placa de um restaurante de ramen com o texto «Ichiban Ramen — Est. 1987», placas de um bar de karaoke e diversos letreiros luminosos. As calçadas molhadas após a chuva refletem as luzes.
Dica de interface/conhecimento do mundo: Uma captura de tela de vídeo do YouTube em estilo foto-realista, mostrando um vídeo intitulado “Como montar um computador em 2026”, com 2,3 milhões de visualizações, incluindo uma barra de comentários realista, vídeos recomendados na barra lateral e informações do canal. Visão de navegador de desktop.
Dica de tela larga: Esta é uma foto cinematográfica em formato widescreen, retratando a fachada de uma loja IKEA ao entardecer, com a sinalização iluminada da IKEA, carros realistas no estacionamento e clientes entrando e saindo. Iluminação do horário dourado, formato 16:9.
Fonte da imagem e referência não indicadas: https://miraflow.ai/blog/how-to-use-duct-tape-ai-model-arena-gpt-image-2-guide
Este artigo é do canal oficial do WeChat "APPSO", autor: Descobrindo produtos do futuro