









Autor: Shenchao TechFlow
Um artigo do Google que afirma ter "reduzido o uso de memória da IA para 1/6" provocou, na semana passada, uma perda de mais de 90 bilhões de dólares em valor de mercado de ações de fabricantes globais de chips de armazenamento, como Micron e SanDisk.
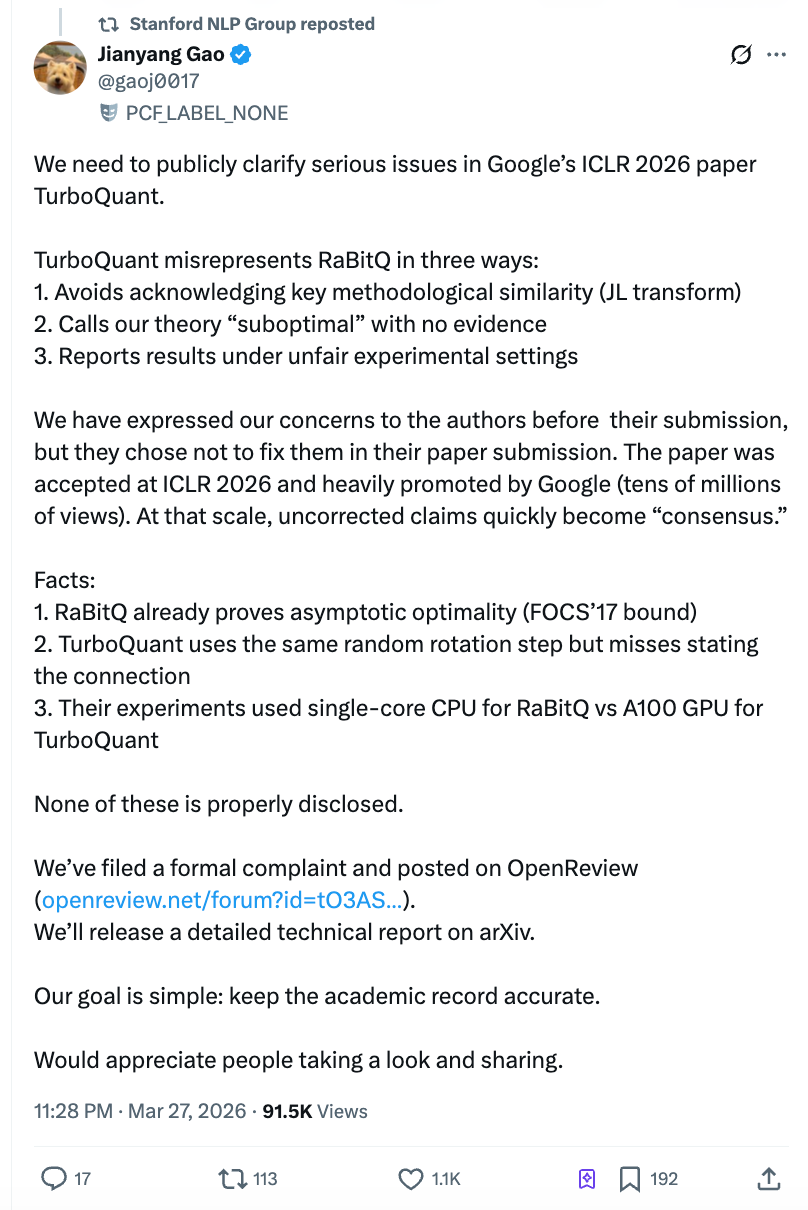
No entanto, apenas dois dias após a publicação do artigo, Gao Jianyang, pós-doutorando do Instituto Federal de Tecnologia de Zurique, publicou uma carta aberta de dez mil palavras acusando a equipe do Google de testar o oponente com um script Python em CPU de único núcleo, enquanto usava GPU A100 para testar a si mesma, e de recusar-se a corrigir o problema mesmo após ser informada antes da submissão. A leitura no Zhihu ultrapassou rapidamente 4 milhões, e a conta oficial do Stanford NLP compartilhou o post, causando agitação simultânea na comunidade acadêmica e no mercado.
(Leitura de referência: Um artigo acadêmico derrubou as ações de armazenamento)
A questão central desta controvérsia não é complexa: um artigo da conferência de IA, amplamente promovido pelo Google oficial e que desencadeou diretamente uma venda em pânico no setor de chips, distorceu sistematicamente um trabalho anterior já publicado e criou uma narrativa falsa de vantagem de desempenho por meio de experimentos injustos deliberadamente?
O que o TurboQuant fez: reduziu o "rascunho" da IA para um sexto do tamanho original
Ao gerar respostas, os grandes modelos de linguagem precisam revisar continuamente os cálculos anteriores. Esses resultados intermediários são armazenados temporariamente na memória VRAM, um processo conhecido na indústria como «KV Cache» (cache de chave-valor). Quanto mais longa for a conversa, mais espessa se torna essa «folha de rascunho», aumentando o consumo de memória VRAM e, consequentemente, os custos.
A equipe de pesquisa do Google desenvolveu o algoritmo TurboQuant, cujo principal atrativo é comprimir este rascunho para 1/6 do tamanho original, ao mesmo tempo em que afirma perda de precisão zero e aumento de até 8 vezes na velocidade de inferência. O artigo foi publicado pela primeira vez na plataforma acadêmica de pré-impressão arXiv em abril de 2025, aceito pela conferência líder na área de IA, ICLR 2026, em janeiro de 2026, e promovido novamente pelo blog oficial do Google em 24 de março.
Do ponto de vista técnico, a abordagem do TurboQuant pode ser simplesmente entendida como: primeiro, aplicar uma transformação matemática para "limpar" os dados desordenados em um formato uniforme, depois comprimi-los individualmente usando uma tabela de compressão otimizada previamente calculada, e finalmente corrigir os desvios computacionais causados pela compressão com um mecanismo de correção de 1 bit. A implementação independente pela comunidade já verificou que o efeito de compressão é essencialmente real, e a contribuição matemática no nível do algoritmo é autêntica.
A controvérsia não está em se o TurboQuant pode ser usado, mas no que o Google fez para provar que ele “ultrapassa em muito os concorrentes”.
Carta aberta de Gao Jianyang: três acusações, todas atingindo o ponto central
Em 27 de março, às 22h, Gao Jianyang publicou um artigo longo no Zhihu e submeteu um comentário formal na plataforma oficial de revisão da ICLR, OpenReview. Gao Jianyang é o autor principal do algoritmo RaBitQ, publicado em 2024 no prestigiado congresso de banco de dados SIGMOD, que aborda o mesmo tipo de problema — compressão eficiente de vetores de alta dimensão.
Suas alegações são divididas em três pontos, cada um comprovado por registros de e-mail e cronologia.
Alegação um: usou o método principal de outra pessoa, sem mencionar em nenhum lugar do texto.
Um passo-chave comum aos núcleos técnicos do TurboQuant e do RaBitQ é realizar uma “rotação aleatória” nos dados antes da compressão. Essa etapa tem como objetivo transformar dados originalmente distribuídos de forma irregular em uma distribuição uniforme previsível, reduzindo significativamente a dificuldade de compressão. Esse é o ponto mais central e mais semelhante entre os dois algoritmos.
O próprio autor do TurboQuant reconheceu isso na resposta à revisão, mas nunca mencionou diretamente a conexão desse método com o RaBitQ no texto completo do artigo. O contexto mais importante é que o segundo autor do TurboQuant, Majid Daliri, entrou em contato ativamente com a equipe de Gao Jianyang em janeiro de 2025, solicitando ajuda para depurar sua versão em Python modificada a partir do código-fonte do RaBitQ. O e-mail descreveu detalhadamente os passos de reprodução e as mensagens de erro — ou seja, a equipe do TurboQuant tinha conhecimento profundo dos detalhes técnicos do RaBitQ.
Um revisor anônimo da ICLR também apontou independentemente que ambos utilizaram a mesma técnica, exigindo uma discussão adequada. Mas na versão final do artigo, a equipe do TurboQuant não apenas não acrescentou discussão, como também moveu a descrição (já incompleta) do RaBitQ, originalmente no corpo principal, para o apêndice.
Acusação dois: afirmar sem fundamentos que a teoria do outro é "subótima".
O artigo do TurboQuant rotulou diretamente o RaBitQ como "subótimo" por causa de uma análise matemática "grossiera". No entanto, Gao Jianyang apontou que a versão expandida do artigo do RaBitQ provou rigorosamente que seu erro de compressão atinge o limite matemático ótimo — uma conclusão publicada no mais prestigiado congresso de ciência da computação teórica.
Em maio de 2025, a equipe de Gao Jianyang explicou detalhadamente a otimalidade da teoria RaBitQ por meio de várias e-mails. Daliri, segundo autor do TurboQuant, confirmou ter informado todos os autores. No entanto, o artigo final ainda manteve a expressão "subótima", sem apresentar quaisquer argumentos de contrariedade.
Acusação três: No experimento comparativo, “esquerda amarrada, direita com faca”.
Esta é a mais impactante de todas as afirmações. Gao Jianyang aponta que o artigo do TurboQuant adicionou duas camadas de condições injustas nos experimentos de comparação de velocidade:
Primeiro, a equipe oficial do RaBitQ forneceu código C++ otimizado (com suporte padrão a paralelismo multithread), mas a equipe do TurboQuant não o utilizou, optando por testar o RaBitQ com sua própria versão traduzida em Python. Segundo, ao testar o RaBitQ, foi utilizado um CPU de único núcleo com multithreading desativado, enquanto o TurboQuant utilizou uma GPU NVIDIA A100.
O efeito combinado dessas duas condições é que o leitor conclui que “RaBitQ é várias ordens de magnitude mais lento que TurboQuant”, sem saber que essa conclusão se baseia na premissa de que a equipe do Google amarrou as mãos e os pés do oponente antes da corrida. Os autores do artigo não divulgaram adequadamente essas diferenças nas condições experimentais.
Resposta do Google: "Girar aleatoriamente é uma técnica geral e não é possível citar cada artigo."
De acordo com Gao Jianyang, a equipe do TurboQuant respondeu por e-mail em março de 2026: "O uso de rotação aleatória e transformação de Johnson-Lindenstrauss já é uma técnica padrão nesse campo, e não podemos citar todos os artigos que utilizam esses métodos."
A equipe de Gao Jianyang considera que isso é uma troca de conceitos: a questão não é se todas as publicações que usaram rotação aleatória devem ser citadas, mas sim que o RaBitQ foi o primeiro trabalho a combinar esse método com compressão vetorial e provar sua otimalidade sob o mesmo conjunto de problemas, e o artigo do TurboQuant deveria descrever com precisão a relação entre ambos.
O perfil oficial do Stanford NLP Group no X retransmitiu a declaração de Gao Jianyang. A equipe de Gao Jianyang já publicou um comentário público na plataforma ICLR OpenReview e apresentou uma reclamação formal ao presidente e ao comitê ético da conferência ICLR; posteriormente, publicarão um relatório técnico detalhado no arXiv.
O blogueiro técnico independente Dario Salvati ofereceu uma avaliação relativamente neutra em sua análise: o TurboQuant realmente fez contribuições reais no método matemático, mas sua relação com o RaBitQ é muito mais estreita do que o artigo sugere.
US$90 bilhões em valor de mercado evaporam: controvérsia do artigo acadêmico somada ao pânico do mercado
O momento em que ocorreu essa controvérsia acadêmica foi extremamente delicado. Após o Google publicar o TurboQuant em seu blog oficial em 24 de março, o setor global de chips de armazenamento sofreu uma forte venda. De acordo com múltiplas mídias, incluindo a CNBC, a Micron Technology caiu por seis dias consecutivos, acumulando uma queda superior a 20%; a SanDisk caiu 11% em um único dia; a SK Hynix da Coreia do Sul caiu cerca de 6%, a Samsung Electronics caiu quase 5% e a Kioxia do Japão caiu cerca de 6%. A lógica de pânico no mercado é simples e direta: a compressão por software pode reduzir a demanda de memória para inferência de IA em seis vezes, levando a uma reavaliação estrutural da perspectiva de demanda por chips de armazenamento.
O analista do Morgan Stanley, Joseph Moore, refutou esse raciocínio em um relatório em 26 de março, mantendo as classificações de “comprar” para Micron e SanDisk. Moore apontou que o TurboQuant comprime apenas um tipo específico de cache, o KV Cache, e não o uso total de memória, classificando-o como uma “melhoria normal de produtividade”. O analista do Wells Fargo, Andrew Rocha, também citou o paradoxo de Jevons, argumentando que aumentos de eficiência que reduzem custos podem, na verdade, estimular uma maior implantação de IA, aumentando por fim a demanda por memória.
Artigo antigo, nova embalagem: risco da cadeia de transmissão da pesquisa em IA para narrativas de mercado
Segundo análise do blogger técnico Ben Pouladian, o artigo do TurboQuant foi publicado oficialmente em abril de 2025 e não é uma nova pesquisa. Em 24 de março, o Google reempacotou e promoveu o artigo por meio de seu blog oficial, mas o mercado o precificou como uma nova ruptura. Essa estratégia de promoção de “artigo antigo, lançamento novo”, combinada com possíveis vieses experimentais no artigo, reflete os riscos sistêmicos na cadeia de transmissão de pesquisas de IA de artigos acadêmicos para narrativas de mercado.
Para investidores em infraestrutura de IA, quando um artigo afirma ter alcançado uma melhoria de desempenho de "várias ordens de grandeza", a primeira pergunta a fazer é se as condições de comparação do benchmark são justas.
A equipe de Gao Jianyang já declarou claramente que continuará impulsionando a resolução formal do problema. O Google ainda não respondeu formalmente às alegações específicas da carta aberta.