









O ajuste de preço do DeepSeek causou uma queda acentuada e não linear, forçando a indústria a entrar em uma nova era de custos.
Autor e fonte do artigo: 0x9999in1, ME News
TL;DR
- Preço rompe o piso: até o final de abril de 2026, o DeepSeek reduziu o preço de saída do modelo V4-Pro para 0,878 dólares por milhão de tokens, combinando descontos temporários e redução de custos de cache, e o preço de entrada com acerto de cache caiu ainda mais para 0,0037 dólares (cerca de 0,025 yuan chinês), rompendo completamente o ponto de referência de precificação da indústria de grandes modelos.
- Há uma lacuna de precificação entre a China e os EUA: em comparação com os principais fabricantes globais, o custo total de chamadas à API do DeepSeek-V4-Pro é apenas cerca de um trigésimo do custo do OpenAI GPT-5.5 e do Anthropic Claude Opus 4.7, criando uma diferença de custo extremamente significativa.
- Pressão sobre o cenário competitivo doméstico: sob a precificação agressiva do DeepSeek, modelos principais como o Zhipu GLM 5.1 e o Moonshot Kimi K2.6 enfrentam forte pressão comercial e podem ser forçados a seguir com reduções de preços, acelerando significativamente a consolidação do setor.
- “Cache hit” torna-se a economia central: DeepSeek reduziu o preço do cache hit para 1/10 do valor original, uma estratégia que beneficia enormemente, na lógica subjacente, os cenários de processamento de textos longos, RAG (Retrieval-Augmented Generation) e interações contínuas e multirround de Agentes.
- Conclusão da análise do think tank: Os modelos base estão acelerando a “infraestruturalização” como água, eletricidade e outros serviços essenciais; o foco da competição futura passará integralmente da disputa pelo tamanho dos parâmetros do modelo para a capacidade de otimização de custos de inferência e a participação no ecossistema de desenvolvedores.
Introdução: O momento "singularidade" do custo de poder de computação de grandes modelos
O avanço tecnológico frequentemente acompanha uma queda exponencial nos custos, um caminho inevitável para qualquer tecnologia disruptiva alcançar adoção generalizada. De 25 a 26 de abril de 2026, a indústria de IA testemunhou um momento altamente marcante: a principal empresa de modelos grandes, DeepSeek, lançou duas "bombas subaquáticas" consecutivas. Primeiro, anunciou uma oferta relâmpago de 25% de desconto para a API do modelo DeepSeek-V4-Pro; em seguida, anunciou que, em todos os serviços de API da série, o preço para acertos de cache de entrada foi reduzido diretamente para 1/10 do preço original.
Após estas duas rodadas de estratégia de ajuste de preços acumuladas, o preço de acerto de cache de entrada para o DeepSeek-V4-Flash caiu para um surpreendente US$ 0,0029 por milhão de tokens antes de 5 de maio de 2026, enquanto o DeepSeek-V4-Pro, comparado aos níveis globais mais avançados, possui um preço de acerto de cache de entrada de apenas US$ 0,0037 (aproximadamente RMB 0,025).
Antes disso, a indústria previa amplamente que o custo de inferência de grandes modelos diminuiria cerca de 50% ao ano, mas o recente ajuste de preços da DeepSeek causou uma queda abrupta e não linear, forçando a indústria a entrar em uma nova era de custos. Acreditamos que isso não é simplesmente uma campanha de marketing ou uma “guerra de preços” de curto prazo, mas sim o resultado inevitável da otimização da arquitetura algorítmica subjacente (como mecanismos de atenção esparsa e evolução extrema da arquitetura MoE) e do aumento da capacidade de engenharia dos clusters de computação. Este relatório, com base nos mais recentes dados de preços de toda a indústria, analisará profundamente o impacto provocado pela redução de preços da DeepSeek e comparará horizontalmente a competitividade comercial dos principais modelos globais, buscando fornecer aos tomadores de decisão um mapa claro da evolução da indústria.
Fenômeno central: Quebra limite do sistema de preços da série DeepSeek-V4
Para compreender a magnitude deste corte de preços, devemos analisar profundamente as três dimensões centrais da cobrança da API de grandes modelos: preço de entrada (sem acerto de cache), preço de entrada (com acerto de cache) e preço de saída. Os modelos anteriores de cobrança geralmente distinguiam apenas entre entrada e saída, mas com o amadurecimento da tecnologia de contexto longo (Long-Context), a "taxa de acerto de cache (Cache Hit)" está se tornando uma variável-chave para redefinir a economia da API.
Análise da estratégia de precificação:叠加 descontos e alavancagem em cache
De acordo com os dados mais recentes divulgados, a DeepSeek adotou uma estratégia de triple impacto: redução de preço base + desconto limitado no tempo + alavancagem de cache.
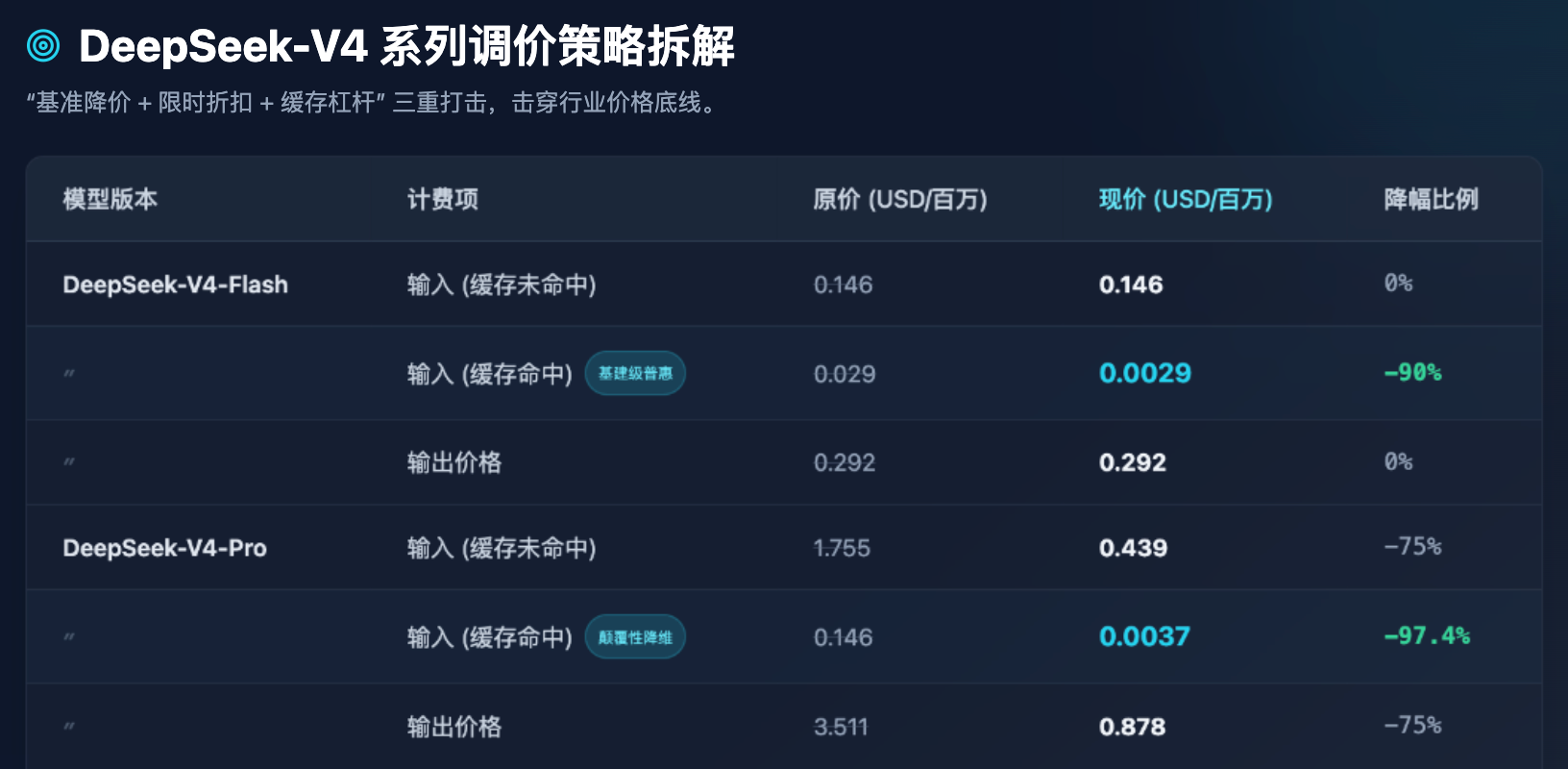
Tabela 1: Comparação antes e depois da nova precificação da série DeepSeek-V4 (em dólares por milhão de tokens)
Da Tabela 1, podemos extrair várias observações industriais extremamente claras:
Em primeiro lugar, a democratização do modelo Flash já atingiu seu limite. Para modelos Flash voltados para alta concorrência e baixa latência, o preço de saída permanece em 0,292 dólares por milhão de tokens, o que já está extremamente próximo do limite mínimo do custo físico da capacidade de processamento dos servidores. A DeepSeek não continuou a ajustar o preço básico do Flash, mas sim reduziu em 90% o preço de "acerto de cache". Isso significa que, ao processar grandes quantidades de prompts de sistema repetitivos ou perguntas e respostas em documentos fixos, o custo do modelo Flash quase pode ser ignorado.
Em segundo lugar, a redução de custo do modelo Pro. O modelo V4-Pro, como um modelo de ponta comparável às primeiras gerações globais (como o GPT-5), viu seu preço de saída cair de US$ 3,511 para US$ 0,878. Ainda mais impressionante: o preço original de entrada para acerto de cache, que era de US$ 0,146, após a aplicação conjunta do desconto temporário de 25% e da redução de 1/10, caiu diretamente para US$ 0,0037. Este é um número extremamente assustador — significa que o custo de acessar a inteligência mais avançada do mundo foi reduzido a um nível em que até pequenas e médias empresas e desenvolvedores individuais podem fazer chamadas frequentes sem nenhuma restrição.
Em terceiro lugar, pressiona os desenvolvedores a otimizarem a engenharia de prompts. Definir o preço de acertos em cache como uma fração significativamente menor do que o preço de falhas (por exemplo, no modelo Pro: US$ 0,0037 contra US$ 0,439, uma diferença de cerca de 118 vezes) não é apenas uma estratégia de precificação, mas também uma forma de orientar o ecossistema tecnológico por meio de meios comerciais. A DeepSeek está claramente informando os desenvolvedores: se o vosso design arquitetural for adequado (por exemplo, colocando o contexto longo fixo na frente e as perguntas curtas variáveis atrás), vocês poderão desfrutar de poder de entrada quase gratuito.
Comparação horizontal: a discrepância acentuada entre os preços dos modelos grandes globais e locais
Comparar apenas verticalmente a redução de preços do DeepSeek por si só não revela a imagem completa; quando o colocamos no sistema de coordenadas do mercado global de modelos grandes em 2026, o contraste “fraturado” criado por essa estratégia de precificação torna-se verdadeiramente arrepiante.
Com base no OpenRouter e nas informações públicas de várias empresas, compilamos os últimos dados de precificação de API dos 9 modelos de linguagem mais representativos do mercado nacional e internacional.

Tabela 2: Comparação dos preços das APIs dos principais modelos globais em 2026 (unidade: dólar por milhão de tokens)
Combatendo gigantes globais: desmantelando o mito da “alta inteligência e alto prêmio”
Nos dois últimos anos de narrativa de IA, a OpenAI e a Anthropic mantiveram um entendimento mútuo: os modelos mais inteligentes devem desfrutar das margens brutas mais altas. Atualmente, os preços de saída do GPT-5.5 e do Claude Opus 4.7 são de até 30 dólares e 25 dólares por milhão de tokens, respectivamente. Essas duas gigantes da Silicon Valley tentam manter seu alto imposto sobre computação monopolizando as capacidades de raciocínio mais avançadas.
No entanto, o surgimento do DeepSeek-V4-Pro e seu preço de saída de US$ 0,878 diretamente rompeu essa fina camada. Supondo que o V4-Pro consiga atingir ou se aproximar do nível do GPT-5,5 em todos os principais testes de desempenho (Benchmarks) e na experiência prática, a diferença de preço de saída de 34 vezes entre os dois destruirá completamente a lógica de prêmio das grandes empresas estrangeiras no mercado B2B.
A «ME News智库» estima que, para uma empresa de exportação altamente dependente de conteúdo gerado por IA, se consumir 1 bilhão de tokens de saída por mês, o custo fixo de uso do GPT-5.5 será de US$ 30.000; já ao alternar para o DeepSeek-V4-Pro, esse custo cairá drasticamente para US$ 878. Essa diferença de custo nessa escala pode determinar a sobrevivência ou falência de uma startup. Isso indica que as empresas chinesas de IA já traçaram um caminho distinto da Silicon Valley, equilibrando eficiência na treinamento de modelos fundamentais e otimização de clusters de inferência, combinando “estética da força bruta” com engenharia extrema.
Cercar colegas domésticos: acelerar a grande reestruturação do setor
Se DeepSeek representa uma vantagem estratégica sobre as grandes empresas estrangeiras, para os concorrentes domésticos, trata-se de um jogo de soma zero cruel.
Da Tabela 2, pode-se ver que fabricantes líderes no mercado doméstico, como Zhipu (GLM 5.1, saída de US$ 4,40) e Moonshot (Kimi K2.6, saída de US$ 4,00), encontram-se em uma situação embaraçosa em termos de precificação. Esses preços eram considerados “razoáveis e com boa relação custo-benefício” há alguns meses, mas diante do DeepSeek-V4-Pro (saída de US$ 0,878), perderam imediatamente toda a sua defesa de preço. Mesmo a Alibaba Cloud, sempre conhecida por ser open-source e de baixo custo (Qwen3.6 Plus, saída de US$ 1,96), já não parece mais “barata”.
No campo dos modelos Flash leves, a batalha também está acirrada. O Step 3.5 Flash da Step星辰 tem entrada tão baixa quanto US$ 0,028 e saída apenas de US$ 0,299, competindo de perto com o DeepSeek-V4-Flash (saída de US$ 0,292). Isso demonstra que, no domínio dos modelos leves, a pressão sobre os custos de computação chegou ao nível nanométrico, com todas as empresas voando praticamente na linha de custo.
Em termos gerais, o DeepSeek está utilizando capacidades de nível Pro para competir com preços de versões Plus ou padrão de concorrentes locais, enquanto aplica preços de nível Flash para capturar todo o volume massivo de tráfego de cauda longa com baixa densidade de valor. Essa tática de “pinça nas duas extremidades” comprime drasticamente o espaço de sobrevivência de outras empresas de modelos de grande porte, acelerando a eliminação dos modelos de IA domésticos após esta rodada de redução de preços.
Visão aprofundada: A tecnologia e a lógica comercial por trás dos preços extremamente baixos
Preços baixos sem fundamentos não são sustentáveis. O DeepSeek ousa adotar uma estratégia de redução de preços tão drástica para 2026 por trás dela há um suporte técnico sólido e uma ambição comercial significativa.
Lógica técnica: Da força bruta à vitória pela arquitetura
A queda acentuada nos preços é, em essência, a liberação dos benefícios da evolução da arquitetura técnica.
- Benefícios profundos da arquitetura MoE (Mixture of Experts): Diferentemente dos grandes modelos densos iniciais da OpenAI, os modelos avançados atuais adotam amplamente uma arquitetura MoE altamente otimizada. É altamente provável que o DeepSeek tenha reduzido ainda mais a proporção de parâmetros ativados na arquitetura V4. Isso significa que, mesmo com um número total de parâmetros elevado, apenas uma pequena fração dos “especialistas” é ativada durante cada inferência, reduzindo significativamente a quantidade de cálculos (FLOPs) e a pressão sobre a largura de banda da memória gráfica por chamada.
- Revolução no gerenciamento do KV Cache: o ponto mais destacado deste ajuste é a redução da taxa de acerto do cache de entrada para 1/10. Na arquitetura Transformer, o maior gargalo na inferência de textos longos não é o cálculo, mas o uso intensivo de memória VRAM pelo KV Cache para armazenar informações de contexto. A DeepSeek claramente implementou, em nível de sistema, uma tecnologia de poolização do KV Cache compartilhado globalmente entre requisições (por exemplo, uma versão aprimorada da tecnologia RadixAttention). Quando inúmeras requisições simultâneas dos usuários contêm configurações do sistema ou bases de conhecimento de fundo idênticas, o modelo não precisa mais recalcular esses tokens, mas sim recuperá-los diretamente da memória ou de um pool distribuído de VRAM. Isso faz com que o custo marginal da entrada de textos longos se aproxime de zero.
Lógica comercial: trocar lucro por espaço, redefinindo o fosso ecológico
A «ME News智库» acredita que o desconto temporário e a estratégia de preço mínimo do DeepSeek têm um objetivo comercial claro e determinado:
Primeiro, destrua completamente o ecossistema de “fine-tuning de carcaça”, forçando o surgimento de aplicações nativas de IA. Quando o custo de chamada dos modelos básicos mais poderosos se aproximar infinitamente do gratuito, será economicamente sem sentido para empreendedores gastarem grandes quantias para treinar ou ajustar seus próprios modelos pequenos de setor. A DeepSeek, por meio de preços baixos, tenta atrair todos os desenvolvedores de IA da sociedade para seu ecossistema de API, tornando-se o “carvão, água e eletricidade” básico da era da IA, como a Amazon AWS ou a Microsoft Azure.
Em segundo lugar, o amanhecer da explosão dos Agentes. Aplicações verdadeiramente agênticas exigem que os modelos realizem grande quantidade de auto-reflexão, planejamento e chamadas cíclicas múltiplas (Loop). Durante esse processo, ocorre um consumo massivo de tokens implícitos. As APIs caras são o maior obstáculo para a adoção de Agentes. O DeepSeek, ao reduzir o preço de acerto de cache para US$ 0,0037, está na verdade tornando economicamente viável “fazer o AI rodar dez mil voltas”. Quem oferecer o custo de tentativa e erro mais baixo será capaz de nutrir o maior superaplicativo nativo de IA.
Impacto e análise de tendências do setor: da "guerra de modelos" para a "guerra de ecossistemas"
Para ilustrar mais claramente o impacto dessa variação de preço nas decisões empresariais, realizamos uma simulação de custos aplicada a casos empresariais.
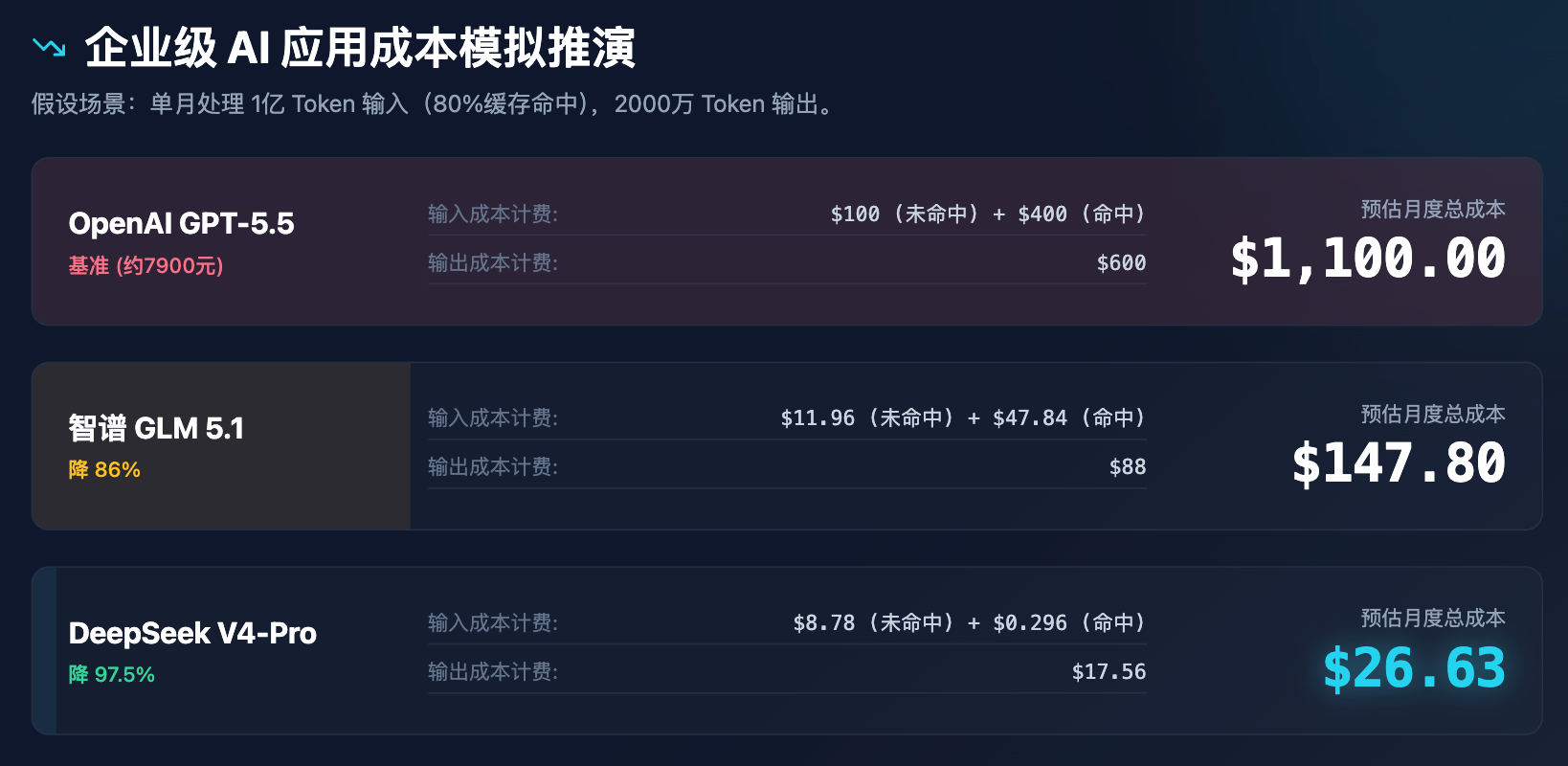
Tabela 3: Análise de simulação de custos para aplicações de IA empresarial (supondo 100 milhões de tokens de entrada e 20 milhões de tokens de saída por mês)
Através da simulação acima, fica claro que a precificação do DeepSeek não está apenas em desconto, mas sim em reestruturar o modelo de custos. Um custo mensal de menos de 30 dólares pode atender a todas as necessidades de assistência ao atendimento ao cliente, análise de documentos e verificação de código de uma empresa média, o que certamente desencadeará uma série de reações em cadeia:
- Mudança fundamental na lógica de investimento em IA: o capital perderá totalmente o interesse em “recriar um grande modelo geral”. Exceto por um número muito reduzido de entidades estatais ou gigantes da internet, a porta para modelos básicos gerais foi soldada. Os investimentos futuros fluirão integralmente em direção à camada de aplicativos (Application Layer) e ao middleware de infraestrutura (roteadores de infraestrutura, gateways de IA, etc.).
- A estratégia de roteamento de múltiplos modelos (LLM Routing) torna-se padrão: as empresas não mais se prenderão a um único modelo. O sistema distribuirá automaticamente as tarefas conforme a complexidade. Por exemplo, 90% da limpeza de dados diária e classificação simples serão realizadas pelo DeepSeek-V4-Flash ou Step 3.5 Flash a um custo extremamente baixo; já 10% das tarefas de raciocínio lógico complexo e geração de relatórios executivos utilizarão o DeepSeek-V4-Pro ou o GPT-5.5 conforme necessário.
- As aplicações de textos longos alcançam um verdadeiro ponto de virada comercial: antes disso, “fazer o upload de relatórios financeiros de milhões de caracteres para que a IA resuma” soava promissor, mas o custo da API, que frequentemente chegava a vários dólares por uso, desencorajava empresas B2B. Com o preço de acerto de cache de entrada reduzido para o nível de 0,02 yuan chinês por milhão de tokens, “ler documentos completos da biblioteca e interagir em tempo real” se tornará uma função padrão em todos os softwares OA e ERP empresariais.
Conclusão e recomendações estratégicas
A queda de preços em abril de 2026 marcou o fim oficial da era clássica e romântica da indústria de grandes modelos, caracterizada por "competir por parâmetros e exibir pontuações", e deu início à era cruel e industrial de "competir por custos, conquistar capacidade de cálculo e dominar ecossistemas". A DeepSeek, por meio de sua estratégia de precificação agressiva, não apenas demonstrou ao mundo a profunda expertise da China em engenharia de modelos de IA, mas também está ativamente estourando a bolha de sobrepreço da capacidade de cálculo de IA.
Para isso, o "ME News Think Tank" tem três sugestões:
- Para desenvolvedores de camada de aplicação: deixem de temer o custo de chamada aos grandes modelos. Pare imediatamente a construção e o fine-tuning de modelos básicos com menos de 10 bilhões de parâmetros e redirecionem todos os recursos de desenvolvimento para a experiência do produto, adaptação em dispositivos locais, construção de barreiras de dados proprietários e aprimoramento de fluxos de trabalho de Agentes. Aproveitem o benefício desta rodada de “computação inteligente barata” para conquistar rapidamente cenários.
- Para CIOs/CTOs de empresas tradicionais: reavalie a estratégia de inteligência artificial da sua empresa. Projetos anteriormente adiados por considerações de custo, como sistemas de perguntas e respostas baseados em conhecimento, atendimento ao cliente automatizado e Copilot de código, agora possuem ROI (retorno sobre o investimento) extremamente alto com os preços atuais de API. Recomenda-se introduzir plataformas maduras de LLMOps e estabelecer uma gateway de IA empresarial para permitir a integração flexível dos modelos mais rentáveis atualmente disponíveis.
- Para concorrentes de modelos básicos: é necessário abandonar a estratégia de acompanhamento. Diante da guerra de preços, ou se otimiza de forma ainda mais extrema a coordenação entre chip e framework para reduzir ainda mais os custos, ou se estabelece barreiras tecnológicas insubstituíveis em áreas diferenciadas, como inteligência embutida, multimodalidade nativa (geração de vídeo/3D) e raciocínio lógico forte em setores verticais. A padronização pura de grandes modelos de linguagem já não oferece saída.
Os grandes modelos já não são deuses confinados aos laboratórios; estão caindo dos altares a uma velocidade sem precedentes, transformando-se em uma onda poderosa que impulsiona a inteligência de tudo. E tudo isso acabou de começar.
Fonte:
- OpenRouter. (2026). Database de Comparação de Preços da API.
- Anúncio Oficial do DeepSeek. (2026, 25 de abril). Plano de oferta limitada para a API DeepSeek-V4-Pro.
- Announcement oficial da DeepSeek. (2026, 26 de abril). Computação acessível na era dos grandes modelos: proposta de ajuste de preços para acerto de cache global da API.