









Artigo | Sleepy.txt
Oito anos atrás, ZTE sofreu uma parada cardíaca.
Em 16 de abril de 2018, uma ordem emitida pelo Bureau of Industry and Security do Departamento de Comércio dos Estados Unidos paralisou ZTE, uma das quatro maiores empresas globais de equipamentos de comunicação, com 80.000 funcionários e receita anual superior a um trilhão, em uma única noite. A ordem era simples: proibir, pelos próximos sete anos, qualquer empresa americana de vender peças, produtos, software e tecnologia à ZTE.
Sem os chips da Qualcomm, as estações base pararam de ser produzidas. Sem a autorização do Android da Google, os celulares não tinham mais um sistema operacional funcional. 23 dias depois, ZTE emitiu um comunicado afirmando que suas principais atividades operacionais já não podiam ser realizadas.
No entanto, ZTE acabou sobrevivendo, mas ao custo de 1,4 bilhão de dólares.
Multa de 1 bilhão de dólares, paga de uma só vez; caução de 400 milhões de dólares, depositada em conta fiduciária em um banco dos EUA. Além disso, toda a alta administração foi substituída e uma equipe de supervisão de conformidade dos EUA foi instalada. Em todo o ano de 2018, ZTE registrou prejuízo líquido de 7 bilhões de yuans e receita caiu 21,4% em relação ao ano anterior.
O então presidente da ZTE, Yin Yimin, escreveu em uma carta interna: "Estamos em uma indústria complexa, altamente dependente da cadeia de suprimentos global." Essa frase, na época, soava como uma reflexão, mas também como um resignação.
Oito anos depois, em 26 de fevereiro de 2026, a unicórnio chinesa de IA DeepSeek anunciou que seu próximo modelo multimodal V4 fará parceria em profundidade com fabricantes nacionais de chips, implementando pela primeira vez uma solução totalmente não NVIDIA, desde o pré-treinamento até o fine-tuning.
We are no longer using NVIDIA.
Assim que a notícia foi divulgada, a primeira reação do mercado foi de ceticismo. A NVIDIA detém mais de 90% da quota de mercado de chips de treinamento de IA globais; abrir mão dela faz sentido do ponto de vista comercial?
Mas por trás da escolha do DeepSeek, esconde-se uma questão maior do que a lógica comercial: que tipo de independência em computação a IA chinesa realmente precisa?
O que realmente está sendo estrangulado?
Muitas pessoas acreditam que a proibição de chips está bloqueando o hardware. Mas o que realmente está sufocando as empresas chinesas de IA é algo chamado CUDA.
CUDA, sigla para Compute Unified Device Architecture, é uma plataforma de computação paralela e modelo de programação lançados pela NVIDIA em 2006. Ela permite que desenvolvedores acessem diretamente a capacidade de processamento da GPU da NVIDIA para acelerar diversas tarefas computacionais complexas.
Antes da chegada da era da IA, era apenas uma ferramenta para poucos entusiastas. Mas quando a onda do aprendizado profundo chegou, a CUDA tornou-se a base de toda a indústria de IA.
O treinamento de grandes modelos de IA é, em essência, uma quantidade massiva de operações matriciais. E isso é exatamente o que as GPU mais bem sabem fazer.
A NVIDIA, com sua estratégia de planejamento antecipado de mais de uma década, construiu uma cadeia de ferramentas completa, desde o hardware de base até aplicações de nível superior, para desenvolvedores de IA em todo o mundo, utilizando a CUDA. Hoje, todos os principais frameworks de IA globais, desde o TensorFlow do Google até o PyTorch da Meta, estão profundamente integrados à CUDA em sua base.
Um doutorando em IA aprende, programa e realiza experimentos em um ambiente CUDA desde o primeiro dia de faculdade. Cada linha de código que ele escreve reforça a vantagem competitiva da NVIDIA.

Até 2025, o ecossistema CUDA já possui mais de 4,5 milhões de desenvolvedores, abrangendo mais de 3.000 aplicativos acelerados por GPU, com mais de 40.000 empresas em todo o mundo utilizando CUDA. Esse número significa que mais de 90% dos desenvolvedores de IA em todo o mundo estão vinculados ao ecossistema da NVIDIA.
O medo do CUDA é que ele é uma roda de inércia. Quanto mais desenvolvedores o utilizam, mais ferramentas, bibliotecas e código são gerados, e mais a ecossistema floresce; quanto mais o ecossistema floresce, mais desenvolvedores são atraídos para se juntar. Uma vez que essa roda de inércia começa a girar, é quase impossível deslocá-la.
O resultado é que a NVIDIA vende a você a pá mais cara e define a única postura de mineração. Você quer trocar de pá? Pode. Mas você terá que reescrever tudo o que foi acumulado nas últimas duas décadas por dezenas de milhares das mentes mais inteligentes do mundo nessa postura: todas as experiências, ferramentas e códigos.
Quem paga esse custo?
Então, em 7 de outubro de 2022, quando as primeiras restrições do BIS entraram em vigor, limitando a exportação para a China das GPUs A100 e H100 da NVIDIA, as empresas chinesas de IA sentiram pela primeira vez uma sensação de sufocamento semelhante à da ZTE. A NVIDIA posteriormente lançou as versões "especiais para a China", A800 e H800, reduzindo a largura de banda de interconexão entre os chips e mantendo apenas suprimentos mínimos.
Mas apenas um ano depois, em 17 de outubro de 2023, o segundo conjunto de restrições foi endurecido novamente, proibindo os A800 e H800, e 13 empresas chinesas foram incluídas na lista de entidades. A NVIDIA foi forçada a lançar novamente uma versão ainda mais limitada, o H20. Em dezembro de 2024, a última rodada de restrições durante o mandato do governo Biden entrou em vigor, restringindo estritamente a exportação do H20.
Três rodadas de restrições, com medidas cada vez mais rigorosas.
Mas desta vez, o rumo da história é totalmente diferente do da ZTE naquela época.
Uma突围 assimétrica
Sob a proibição, todos acreditaram que o sonho da China com modelos de grande porte de IA terminaria ali.
Eles estão todos errados. Diante do bloqueio, as empresas chinesas não escolheram confrontar diretamente, mas sim iniciar uma突围. O primeiro campo de batalha dessa突围 não está nos chips, mas nos algoritmos.
De finais de 2024 a 2025, as empresas chinesas de IA migraram coletivamente para uma direção tecnológica: modelos especialistas híbridos.
Em poucas palavras, consiste em dividir um modelo grande em vários pequenos especialistas, ativando apenas os mais relevantes para cada tarefa, em vez de acionar todo o modelo.
O V3 do DeepSeek é um exemplo típico dessa abordagem. Ele possui 671 bilhões de parâmetros, mas durante cada inferência, apenas 37 bilhões são ativados, representando apenas 5,5% do total. Em termos de custo de treinamento, ele utilizou 2048 GPUs NVIDIA H800, treinando por 58 dias, com um custo total de 5,576 milhões de dólares. Para comparação, as estimativas externas sobre o custo de treinamento do GPT-4 estão em torno de 78 milhões de dólares. Uma diferença de uma ordem de grandeza.
A otimização extrema no algoritmo se refletiu diretamente nos preços. O preço da API do DeepSeek é de apenas US$ 0,028 a US$ 0,28 por milhão de tokens de entrada e US$ 0,42 para saída. Já o GPT-4o cobra US$ 5 por entrada e US$ 15 por saída. O Claude Opus é ainda mais caro, com US$ 15 por entrada e US$ 75 por saída. Em termos comparativos, o DeepSeek é de 25 a 75 vezes mais barato que o Claude.
Essa diferença de preço gerou grande repercussão no mercado global de desenvolvedores. Em fevereiro de 2026, na OpenRouter, a maior plataforma agregadora de API de modelos de IA do mundo, o volume semanal de chamadas aos modelos de IA chineses aumentou 127% em três semanas, superando pela primeira vez os Estados Unidos. Um ano atrás, a participação dos modelos chineses na OpenRouter era inferior a 2%. Um ano depois, cresceu 421%, aproximando-se de 60%.
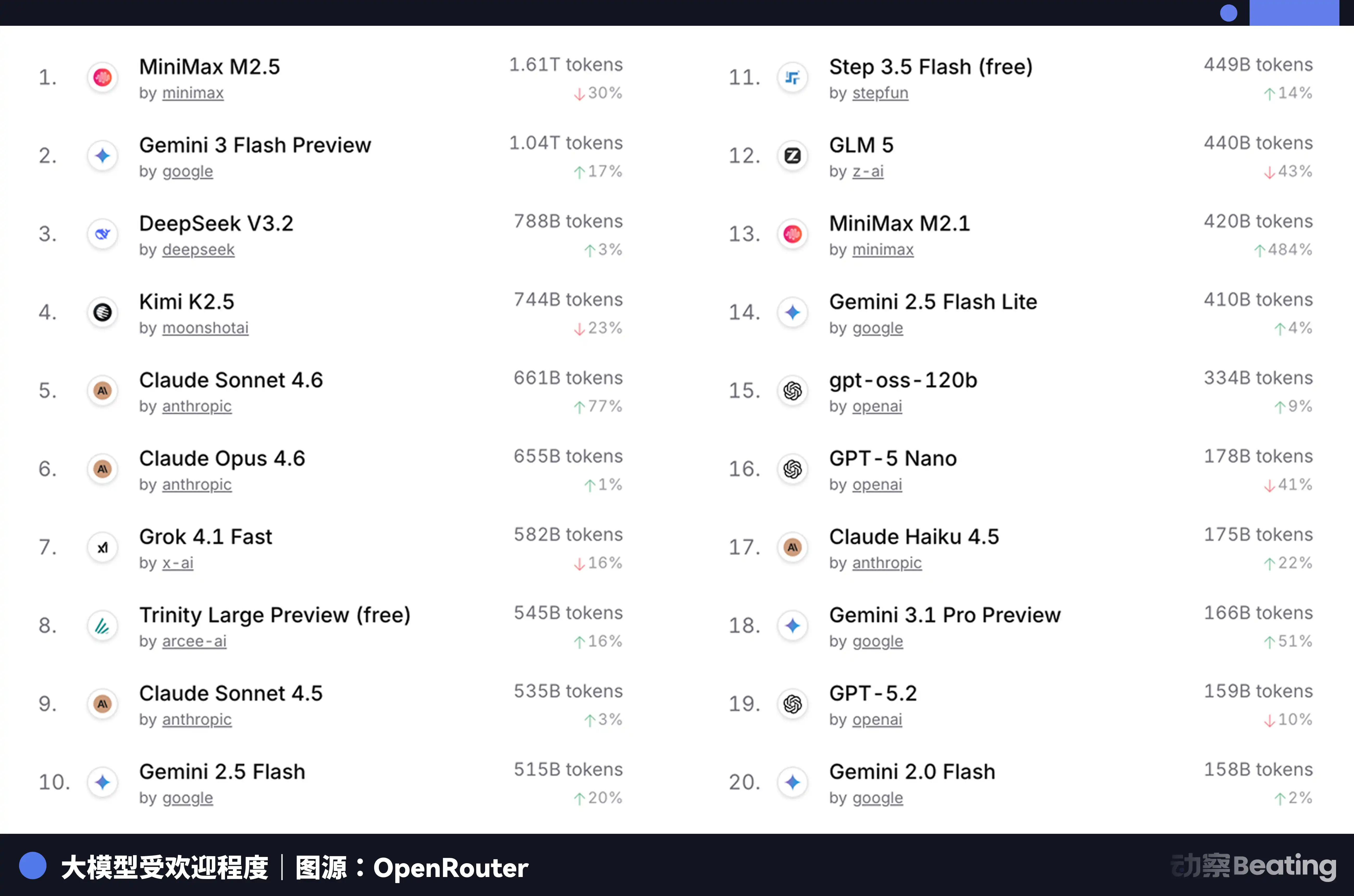
Por trás desses dados, há uma mudança estrutural facilmente ignorada. A partir do segundo semestre de 2025, o cenário principal das aplicações de IA passou de chat para Agent. Em cenários de Agent, o consumo de Token por tarefa é de 10 a 100 vezes maior do que em chat simples. Quando o consumo de Token cresce exponencialmente, o preço se torna o fator decisivo. A extrema relação custo-benefício dos modelos chineses coincidiu exatamente com essa janela.
Mas o problema é que a redução dos custos de inferência não resolve o problema fundamental do treinamento. Um grande modelo, se não puder ser continuamente treinado e iterado com os dados mais recentes, sua capacidade degradará rapidamente. E o treinamento continua sendo aquele buraco negro de poder computacional que não pode ser ignorado.
Então, de onde vêm as "pás" treinadas?
Promoção do backup
Jiangsu Xinghua, uma pequena cidade no sul de Jiangsu, conhecida por aço inoxidável e alimentos saudáveis, anteriormente não tinha nenhuma relação com IA. Mas em 2025, uma linha de produção nacional de servidores de poder de computação, com 148 metros de comprimento, foi construída e colocada em operação aqui, levando apenas 180 dias desde a assinatura do contrato até a produção.
O núcleo desta linha de produção são dois chips totalmente nacionais: o processador Loongson 3C6000 e o acelerador AI TaiChu YuanQi T100. O Loongson 3C6000 possui arquitetura de instruções e microarquitetura totalmente desenvolvidas internamente. O TaiChu YuanQi foi derivado da equipe do Centro Nacional de Supercomputação de Wuxi e da Universidade Tsinghua, utilizando arquitetura híbrida de múltiplos núcleos.
Quando a linha de produção estiver operando em plena capacidade, um servidor será produzido a cada 5 minutos. O investimento total nesta linha de produção é de 1,1 bilhão de yuans, com uma produção anual prevista de 100.000 unidades.
Mais importante ainda, com base nesses chips nacionais, clusters de dez mil GPUs já começaram a executar tarefas reais de treinamento de grandes modelos.
Em janeiro de 2026, Zhipu AI, em parceria com a Huawei, lançou o GLM-Image, o primeiro modelo SOTA de geração de imagens treinado integralmente com chips nacionais. Em fevereiro, o modelo grande de trilhões de parâmetros "Xingchen" da China Telecom completou o treinamento completo no pool de capacidade de cálculo nacional de dez mil unidades em Lingang, Xangai.

O significado desses casos é que eles provam um ponto: os chips nacionais já passaram da fase de “capazes de inferência” para “capazes de treinamento”. Isso é uma mudança qualitativa. A inferência requer apenas a execução de modelos já treinados, com requisitos relativamente baixos para os chips; já o treinamento exige processar quantidades massivas de dados, realizar cálculos complexos de gradiente e atualizações de parâmetros, exigindo dos chips potência de cálculo, largura de banda de interconexão e ecossistema de software em uma ordem de grandeza superior.
A força central por trás dessas tarefas é a série de chips Ascend da Huawei. Até o final de 2025, o número de desenvolvedores no ecossistema Ascend ultrapassou 4 milhões, com mais de 3.000 parceiros, 43 dos principais modelos grandes da indústria concluíram o pré-treinamento com base no Ascend e mais de 200 modelos open source foram adaptados. Na MWC de 2 de março de 2026, a Huawei lançou globalmente a nova base de poder de computação SuperPoD.
A capacidade de processamento FP16 do Ascend 910B já está alinhada com a NVIDIA A100. Embora ainda exista uma diferença, ela passou de inviável para viável, e está evoluindo para ser mais utilizável. A construção do ecossistema não pode aguardar até que o chip esteja perfeito; deve ser amplamente implementado já na fase em que for suficiente, usando demandas reais de negócios para impulsionar a iteração do chip e do software. Os objetivos de adoção de servidores de computação nacional por ByteDance, Tencent e Baidu para 2026 geralmente dobram em relação ao ano anterior. Dados do Ministério da Indústria e da Tecnologia da Informação mostram que a escala de computação inteligente da China já atingiu 1590 EFLOPS. Em 2026, está se tornando o ano de início da implantação em larga escala da computação nacional.
Apagão nos Estados Unidos e a expansão chinesa no exterior
No início de 2026, a Virgínia, que suporta grande parte do tráfego de data centers globais, suspendeu a aprovação de novos projetos de data centers. A Geórgia seguiu o exemplo, prorrogando a suspensão da aprovação até 2027. Illinois e Michigan também implementaram medidas restritivas.
De acordo com dados da Agência Internacional de Energia, os centros de dados dos Estados Unidos consumiram 183 terawatt-horas em 2024, correspondendo a cerca de 4% do consumo total de eletricidade do país. Até 2030, esse número deverá dobrar para 426 TWh, podendo ultrapassar 12% da participação. O CEO da Arm prevê ainda que, até 2030, os centros de dados de IA consumirão de 20% a 25% da eletricidade dos Estados Unidos.
A rede elétrica dos Estados Unidos já está sobrecarregada. A rede PJM, que abrange 13 estados do leste dos EUA, enfrenta uma escassez de capacidade de 6 GW. Até 2033, os Estados Unidos como um todo enfrentarão uma lacuna de capacidade elétrica de 175 GW, equivalente ao consumo de energia de 130 milhões de lares. O custo atacadista de energia nas regiões concentradas de data centers aumentou 267% em relação a cinco anos atrás.
O limite da capacidade de mineração é a energia. E nesse aspecto, a diferença entre China e EUA é maior do que a dos chips, apenas com a direção invertida.
A geração de energia da China é de 10,4 trilhões de quilowatt-horas, dos Estados Unidos é de 4,2 trilhões de quilowatt-horas, ou seja, a China é 2,5 vezes maior que os Estados Unidos. Mais importante ainda, o consumo residencial na China representa apenas 15% do consumo total de energia, enquanto nos Estados Unidos essa proporção é de 36%. Isso significa que a China possui muito mais capacidade de energia industrial disponível para investir em infraestrutura de computação do que os Estados Unidos.
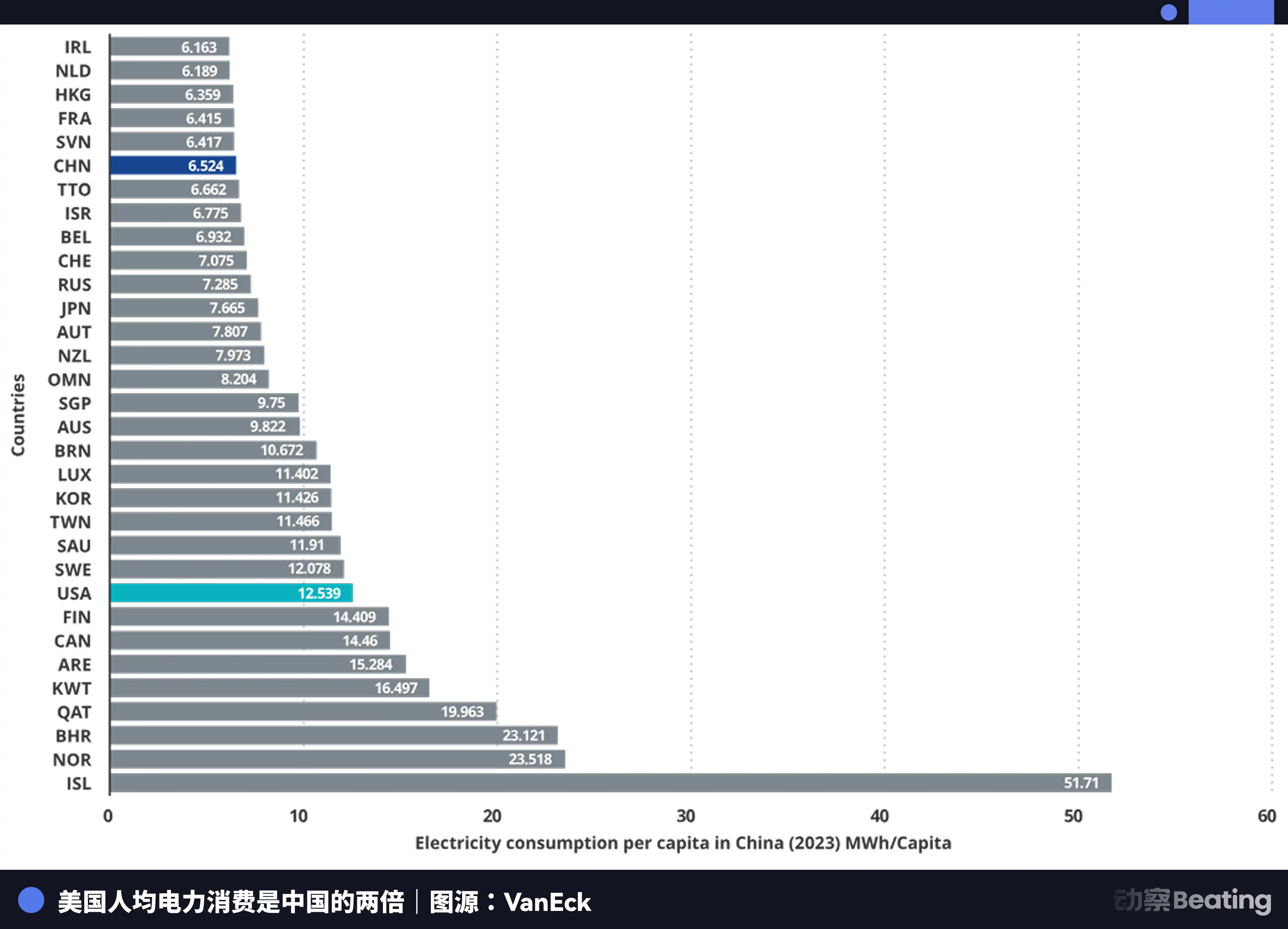
Em termos de tarifas de energia elétrica, as regiões dos EUA onde as empresas de IA estão concentradas têm tarifas de 0,12 a 0,15 dólares por quilowatt-hora, enquanto as tarifas industriais na China ocidental são de aproximadamente 0,03 dólares, apenas um quarto a um quinto do valor nos EUA.
O aumento da geração de energia da China já atingiu sete vezes o da América.
Enquanto os Estados Unidos se preocupam com a energia, a IA da China está silenciosamente se expandindo para o exterior. Mas desta vez, o que está saindo não é um produto, nem uma fábrica, mas um Token.
Token, a unidade mínima de informação processada por modelos de IA, está se tornando um novo bem digital. Ele é produzido em fábricas de poder de computação na China e transmitido globalmente por cabos submarinos.
Os dados de distribuição de usuários do DeepSeek são muito esclarecedores: 30,7% na China, 13,6% na Índia, 6,9% na Indonésia, 4,3% nos Estados Unidos e 3,2% na França. Ele suporta 37 idiomas e é muito popular em mercados emergentes como o Brasil. Mais de 26.000 empresas globais abriram contas, e 3.200 instituições implantaram a versão empresarial.
Em 2025, 58% das novas startups de IA incorporaram o DeepSeek em sua pilha tecnológica. Na China, o DeepSeek detém 89% do mercado. Em outros países sob sanções, as quotas de mercado variam entre 40% e 60%.
Esta cena lembra muito a outra guerra sobre a autonomia industrial há quarenta anos.
Em 1986, em Tóquio, sob forte pressão dos Estados Unidos, o governo japonês assinou o Acordo Semicondutor EUA-Japão. Os principais termos do acordo eram três: exigir que o Japão abrisse seu mercado de semicondutores, garantindo que a participação de mercado de chips americanos no Japão atingisse mais de 20%; proibir a exportação de semicondutores japoneses a preços inferiores ao custo; e impor uma tarifa punitiva de 100% sobre 300 milhões de dólares em chips exportados pelo Japão. Ao mesmo tempo, os Estados Unidos rejeitaram a aquisição da Fairchild Semiconductor pela Fujitsu.
Naquele ano, a indústria japonesa de semicondutores estava no auge. Em 1988, o Japão controlava 51% do mercado global de semicondutores, enquanto os Estados Unidos tinham apenas 36,8%. Das dez maiores empresas de semicondutores do mundo, seis eram japonesas: NEC em segundo lugar, Toshiba em terceiro, Hitachi em quinto, Fujitsu em sétimo, Mitsubishi em oitavo e Panasonic em nono. Em 1985, a Intel sofreu um prejuízo de US$ 173 milhões na disputa semicondutora entre EUA e Japão, à beira da falência.
Mas após a assinatura do contrato, tudo mudou.
Os Estados Unidos lançaram uma repressão abrangente contra empresas japonesas de semicondutores por meio de investigações como a Seção 301, ao mesmo tempo em que apoiaram a Samsung e a SK Hynix da Coreia do Sul para invadir o mercado japonês com preços mais baixos. A participação japonesa em DRAM caiu de 80% para 10%. Em 2017, a quota de mercado japonesa em CI era de apenas 7%. Os gigantes antes dominantes foram ou divididos, ou adquiridos, ou se retiraram silenciosamente amidas perdas intermináveis.
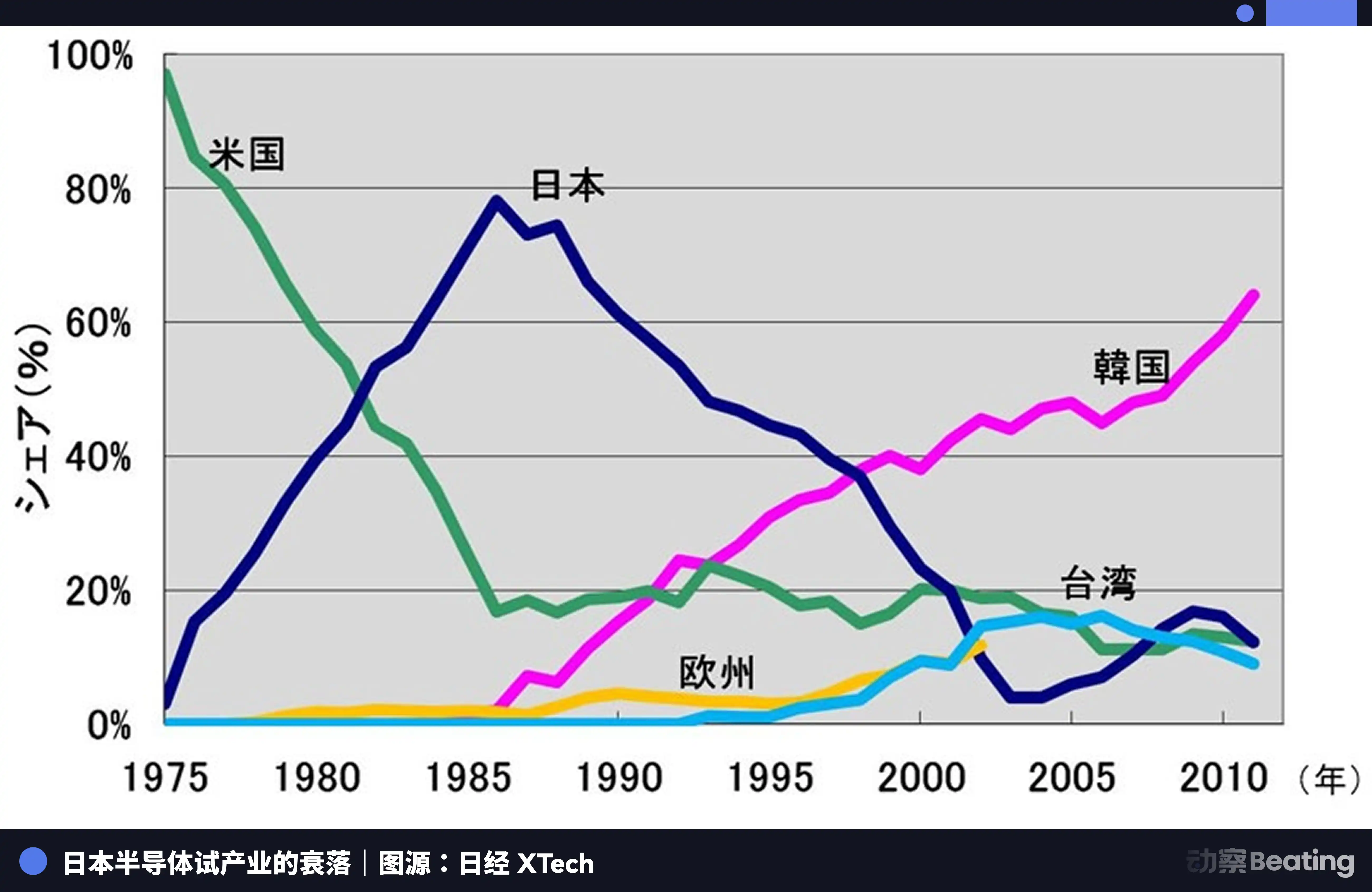
A tragédia dos semicondutores japoneses está em ter-se contentado em ser o melhor produtor em um sistema global de divisão de trabalho dominado por uma única força externa, sem jamais tentar construir seu próprio ecossistema independente. Quando a maré baixou, descobriu que, além da produção, não tinha nada.
A indústria chinesa de IA de hoje está em uma encruzilhada semelhante, mas completamente diferente.
Semelhantemente, também enfrentamos grande pressão externa. Três rodadas de restrições de chips, cada vez mais rigorosas, e as barreiras da ecossistema CUDA permanecem altas.
Diferentemente disso, desta vez escolhemos um caminho mais difícil: desde a otimização extrema no nível de algoritmos, até a transição de chips nacionais da inferência para o treinamento, passando pelo acúmulo de 4 milhões de desenvolvedores no ecossistema Ascend e pela penetração dos tokens no mercado global. Cada passo nesse caminho está construindo um ecossistema industrial independente que o Japão nunca teve.
Epílogo
Em 27 de fevereiro de 2026, três relatórios de desempenho de empresas locais de chips de IA foram publicados no mesmo dia.
Cambricon, receita aumentou 453%, alcançando lucro anual pela primeira vez. Moore Threads, receita cresceu 243%, mas teve prejuízo líquido de 1 bilhão. Moxi, receita aumentou 121%, prejuízo líquido de quase 800 milhões.
Metade é fogo, metade é água.
Chamas são a extrema fome do mercado. Os 95% de espaço deixados por Huang Renxun estão sendo preenchidos, centímetro por centímetro, pelos números de receita dessas empresas locais. Independentemente do desempenho ou do ecossistema, o mercado precisa de uma segunda opção além da NVIDIA. Esta é uma oportunidade estrutural única, aberta pela geopolítica.
A água do mar é um custo enorme para a construção ecológica. Cada perda é dinheiro real pago para alcançar o ecossistema CUDA. São investimentos em pesquisa e desenvolvimento, subsídios para software e custos com engenheiros enviados aos locais dos clientes para resolver individualmente problemas de compilação. Essas perdas não são resultado de má gestão, mas sim o imposto de guerra necessário para construir um ecossistema independente.
Estes três balanços registraram com mais honestidade a realidade desta guerra de hash do que qualquer relatório setorial. Não foi uma vitória triunfante, mas uma batalha de trincheiras sangrenta, avançando enquanto sangrava.
Mas a forma da guerra realmente mudou. Oito anos atrás, discutíamos a questão de “se conseguiremos sobreviver”. Hoje, discutimos a questão de “quanto custará sobreviver”.
O próprio custo é progresso.
Clique para saber mais sobre as vagas em aberto na BlockBeats
Bem-vindo ao grupo oficial da BlockBeats:
Grupo de assinatura no Telegram: https://t.me/theblockbeats
Grupo de Telegram: https://t.me/BlockBeats_App
Conta oficial no Twitter: https://twitter.com/BlockBeatsAsia