










Autor original: KarenZ, Foresight News
Em 20 de março de 2026, houve uma conversa incomum no podcast de venture capital All-In.
O investidor de risco Chamath Palihapitiya passou a bola para o CEO da NVIDIA, Jensen Huang, dizendo que um projeto no Bittensor "realizou uma conquista técnica bastante louca": treinou um grande modelo de linguagem na internet usando poder computacional distribuído, totalmente descentralizado, sem qualquer data center centralizado envolvido.
Huang Renxun não evitou. Ele comparou o assunto à versão moderna do Folding@home, um projeto distribuído que, nos anos 2000, permitiu que usuários comuns contribuíssem com sua capacidade de processamento ociosa para combater o desafio do dobramento de proteínas.
Quatro dias antes, em 16 de março, Jack Clark, cofundador da Anthropic, também dedicou grande parte de um relatório sobre avanços em pesquisa de IA a esta conquista: a sub-rede do ecossistema Bittensor, Templar (SN3), concluiu o treinamento distribuído de um modelo grande com 72 bilhões de parâmetros (Covenant 72B), cujo desempenho é equivalente ao do LLaMA-2 lançado pela Meta em 2023.
Jack Clark intitulou este capítulo de "Desafiando a Política Econômica da IA por meio do Treinamento Distribuído" e, em sua análise, enfatizou que se trata de uma tecnologia digna de acompanhamento contínuo — ele consegue imaginar um futuro no qual a IA em dispositivos adote amplamente modelos treinados de forma descentralizada, enquanto a IA na nuvem continua a executar modelos grandes proprietários.
A reação do mercado foi ligeiramente atrasada, mas muito intensa: o SN3 subiu mais de 440% no último mês e mais de 340% nas últimas duas semanas, com uma capitalização de mercado de US$ 130 milhões. A explosão da narrativa da sub-rede transmitirá diretamente pressão de compra para o TAO. Por isso, o TAO subiu rapidamente, atingindo temporariamente US$ 377, dobrando seu valor no último mês, com uma FDV de aproximadamente US$ 7,5 bilhões.
A questão é: o que o SN3 realmente fez? Por que foi colocado sob os holofotes? Como evoluirá a narrativa de valor do treinamento distribuído e da IA descentralizada?
Esse modelo de 72B
Para responder a essa pergunta, é preciso primeiro analisar o desempenho do SN3.
Em 10 de março de 2026, a equipe Covenant AI publicou um relatório técnico no arXiv, anunciando oficialmente que o Covenant-72B foi treinado. Este é um modelo de linguagem grande com 72 bilhões de parâmetros, treinado em aproximadamente 1,1 trilhão de tokens, utilizando mais de 70 nós independentes (cerca de 20 nós sincronizados por rodada, cada um equipado com 8 B200).
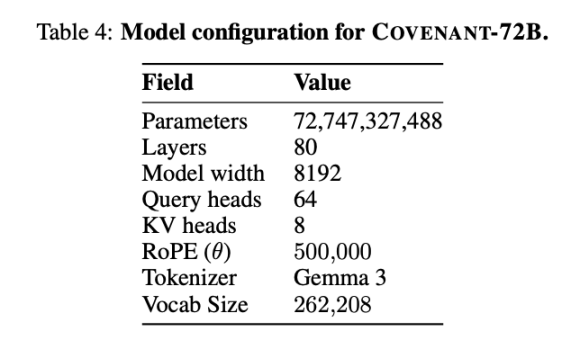
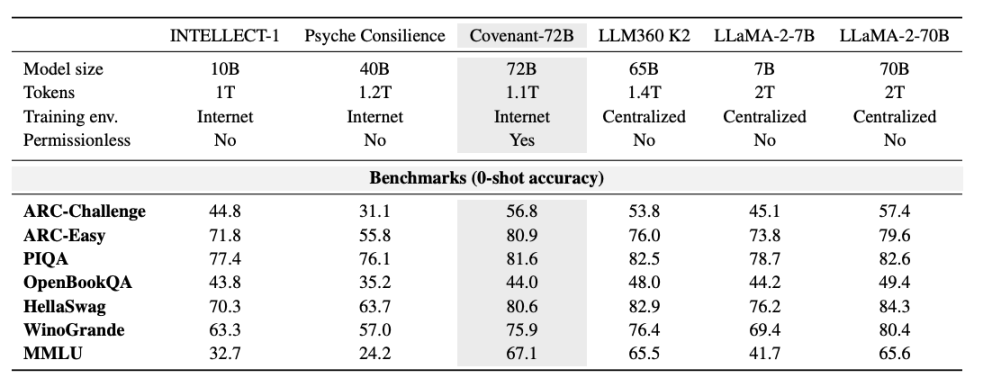
O Templar apresentou alguns dados em termos de benchmark, sendo que o LLaMA-2-70B comparado foi o grande modelo lançado pela Meta em 2023. Como afirmou Jack Clark, cofundador da Anthropic, o Covenant-72B pode estar obsoleto em 2026. A pontuação de 67,1 do Covenant-72B no MMLU corresponde aproximadamente à do LLaMA-2-70B da Meta (65,6 pontos), lançado em 2023.
Enquanto os modelos de ponta de 2026 — seja da série GPT, Claude ou Gemini — já foram treinados em centenas de milhares de GPUs com parâmetros muito superiores a 100 bilhões, a lacuna em capacidades de inferência, codificação e matemática é de ordens de grandeza, não de porcentagens. Essa realidade não deve ser submersa pelo humor do mercado.
Mas, sob o pressuposto de "treinado com poder de computação distribuído na internet aberta", o significado é completamente diferente.
Faça uma comparação: o INTELLECT-1 (desenvolvido pela equipe Prime Intellect, 10 bilhões de parâmetros), treinado de forma descentralizada, obteve pontuação MMLU de 32,7; outro projeto de treinamento distribuído, Psyche Consilience (40 bilhões de parâmetros), realizado entre participantes autorizados, obteve pontuação de 24,2. O Covenant-72B, com escala de 72B e pontuação MMLU de 67,1, é um número notável na categoria de treinamento descentralizado.
Mais importante ainda, este treinamento é “sem permissão”. Qualquer pessoa pode se conectar como nó participante, sem necessidade de aprovação prévia ou lista de permissões. Mais de 70 nós independentes participaram da atualização do modelo, contribuindo com poder de processamento de diversas regiões do mundo.
O que Huang Renxun disse e o que não disse
Revisitar os detalhes da conversa do podcast ajuda a corrigir a interpretação externa desse "endosso".
Chamath Palihapitiya apresentou as conquistas técnicas do Bittensor na conversa a黄仁勋, descrevendo-o como um modelo Llama treinado com poder computacional distribuído, de forma "totalmente distribuída, mantendo o estado ao mesmo tempo". A resposta de 黄仁勋 foi comparar isso a uma "versão moderna do Folding@home", e expandir a discussão sobre a necessidade da coexistência paralela de modelos abertos e proprietários.
É importante notar que Huang Renxun não mencionou diretamente o token do Bittensor ou qualquer implicação de investimento, nem discutiu mais a fundo o treinamento descentralizado de IA.
Entenda as sub-redes do Bittensor e o SN3
Para entender a ruptura do SN3, primeiro é necessário compreender o funcionamento do Bittensor e suas sub-redes. Em termos simples, o Bittensor pode ser visto como uma blockchain e plataforma de IA, e cada sub-rede equivale a uma “linha de produção de IA” independente, com tarefas centrais bem definidas, mecanismos de incentivo próprios e que colaboram para formar um ecossistema descentralizado de IA.
Seu funcionamento é claro e descentralizado: os proprietários das subredes definem os objetivos da subrede e criam modelos de incentivo; os mineiros fornecem poder de processamento dentro da subrede e concluem tarefas relacionadas à IA (como inferência, treinamento, armazenamento, etc.); os validadores avaliam as contribuições dos mineiros e enviam essas pontuações para a camada de consenso do Bittensor; por fim, o algoritmo de consenso Yuma do Bittensor distribui os rendimentos correspondentes aos participantes da subrede com base nos prêmios acumulados em cada subrede.
Atualmente, existem 128 sub-redes no Bittensor, cobrindo diversos tipos de tarefas de IA, como inferência, serviços de nuvem AI sem servidor, imagens, rotulagem de dados, aprendizado por reforço, armazenamento e computação.
E o SN3 é uma dessas sub-redes. Ele não atua como uma camada de aplicação, nem aluga APIs de grandes modelos prontos, mas sim ataca diretamente um dos segmentos mais caros e fechados da cadeia de valor da IA: o próprio pré-treinamento de grandes modelos.
SN3 deseja utilizar a rede Bittensor para coordenar o treinamento distribuído de recursos de computação heterogêneos, provando, por meio de treinamento distribuído incentivado de grandes modelos, que é possível treinar modelos fundamentais poderosos sem depender de caros clusters centralizados de supercomputadores. Atração central reside na "igualdade" — quebrar o monopólio de recursos no treinamento centralizado, permitindo que indivíduos comuns ou pequenas e médias instituições participem do treinamento de grandes modelos, ao mesmo tempo em que reduzem os custos de treinamento por meio de capacidade computacional distribuída.
A força motriz por trás do desenvolvimento do SN3 é o Templar, cuja equipe de pesquisa é a Covenant Labs. Essa equipe também opera outros dois subredes: Basilica (SN39, focada em serviços de computação) e Grail (SN81, focada em pós-treinamento RL e avaliação de modelos). Os três subredes formam uma integração vertical, cobrindo integralmente todo o fluxo de trabalho de grandes modelos, desde o pré-treinamento até a otimização de alinhamento, construindo um ecossistema completo de treinamento descentralizado de grandes modelos.
Especificamente, os mineiros contribuem com recursos de computação, enviando para a rede as atualizações de gradiente (direção e intensidade dos ajustes dos parâmetros do modelo); os validadores avaliam a qualidade da contribuição de cada mineiro, atribuindo pontuações na cadeia com base no grau de melhoria do erro. Os resultados determinam os pesos de recompensa, que são alocados automaticamente, sem necessidade de confiar em terceiros.
A chave no design do mecanismo de incentivo é que os prêmios estejam diretamente ligados ao quanto sua contribuição melhorou o modelo, e não apenas à disponibilidade de poder de processamento. Isso resolve, fundamentalmente, o problema mais difícil em cenários descentralizados: como impedir que os mineiros negligenciem suas responsabilidades.
Como o Covenant-72B resolve os problemas de eficiência de comunicação e compatibilidade de incentivos?
Coordenar dezenas de nós que não se confiam mutuamente, com hardware diverso e qualidade de rede variável para treinar o mesmo modelo apresenta dois desafios: primeiro, a eficiência de comunicação — soluções padrão de treinamento distribuído exigem interconexão de alta largura de banda e baixa latência entre os nós; segundo, a compatibilidade de incentivos — como evitar que nós maliciosos enviem gradientes incorretos? Como garantir que cada participante esteja realmente treinando, e não apenas copiando os resultados dos outros?
SN3 resolve esses dois problemas com dois componentes principais: SparseLoCo e Gauntlet.
SparseLoCo resolve problemas de eficiência de comunicação. O treinamento distribuído tradicional exige sincronização de gradientes completos a cada etapa, gerando volumes de dados enormes. A abordagem adotada pelo SparseLoCo é: cada nó executa 30 etapas de otimização local (AdamW) e, em seguida, comprime os "gradientes falsos" gerados antes de enviá-los aos outros nós. Os métodos de compressão incluem esparsificação Top-k (manter apenas os componentes de gradiente mais críticos), feedback de erro (armazenar as partes descartadas para acumular na próxima rodada) e quantização de 2 bits. A razão de compressão final excede 146 vezes.
Em outras palavras, o que antes precisava de 100 MB de transmissão agora requer menos de 1 MB.
Isso permite que o sistema mantenha a utilização de computação em cerca de 94,5% sob os limites de largura de banda da internet comum (110 Mbps de upload, 500 Mbps de download) — 20 nós, 8 B200 por nó, com apenas 70 segundos por ciclo de comunicação.
A Gauntlet resolve o problema de compatibilidade de incentivos. Ela opera na blockchain Bittensor (Subnet 3) e é responsável por validar a qualidade dos pseudo-gradientes enviados por cada nó. O método consiste em testar, com um pequeno lote de dados, "quanto a perda do modelo reduziu após aplicar o gradiente desse nó"; o resultado é chamado de LossScore. Além disso, o sistema verifica se o nó está treinando com os dados atribuídos a ele — se um nó apresentar melhora na perda em dados aleatórios melhor do que nos dados que lhe foram atribuídos, recebe uma pontuação negativa.
Finalmente, apenas os gradientes dos nós com as pontuações mais altas são selecionados para agregação em cada rodada, enquanto os demais são eliminados dessa rodada. Participantes adicionais são substituídos conforme necessário para manter o sistema estável. Ao longo de todo o processo de treinamento, em média, os gradientes de 16,9 nós por rodada são incluídos na agregação, com mais de 70 IDs únicos de nós participando ao longo do tempo.
A narrativa de valor da IA descentralizada está passando por uma transformação fundamental
Do ponto de vista técnico e industrial, o rumo representado pelo Covenant-72B tem várias implicações reais.
Primeiro, desafiou a suposição de que o treinamento distribuído só é adequado para modelos pequenos. Embora ainda esteja longe dos modelos de ponta, demonstrou a escalabilidade dessa abordagem.
Em segundo lugar, a participação sem permissão é viável e real. Este ponto foi subestimado. Projetos anteriores de treinamento distribuído dependiam de listas brancas — apenas participantes aprovados podiam contribuir com poder de processamento. Neste treinamento do SN3, qualquer pessoa com poder de processamento suficiente pode se conectar, e o mecanismo de verificação filtra contribuições maliciosas. Este é um passo concreto rumo à “descentralização verdadeira”.
Em terceiro lugar, o mecanismo dTAO do Bittensor possibilita a descoberta de mercado do valor das sub-redes. O dTAO permite que cada sub-rede emita seu próprio token Alpha, permitindo que o mercado, por meio do mecanismo AMM, determine quais sub-redes recebem mais emissões de TAO. Isso fornece um mecanismo de captura de valor, embora rudimentar e eficaz, para sub-redes como a SN3, que produziram resultados concretos. Claro, esse mecanismo também é suscetível a interferências de narrativas e emoções, pois a qualidade dos resultados de treinamento de LLMs é difícil de ser avaliada independentemente pelos participantes comuns do mercado.
Quarto, as implicações político-econômicas do treinamento descentralizado de IA. Jack Clark, no Import AI, elevou essa questão ao nível de “quem possui o futuro da IA”. Atualmente, o treinamento de modelos de ponta é monopolizado por poucas instituições que possuem grandes centros de dados, o que não é apenas um problema comercial, mas também uma questão de estrutura de poder. Se o treinamento distribuído continuar a avançar tecnicamente, poderá, em certos tipos de modelos (como pequenos modelos de ponta em domínios específicos), formar um ecossistema de desenvolvimento verdadeiramente descentralizado. Claro, esse cenário ainda está muito distante.
Resumo: Um marco real, além de uma série de problemas reais
Huang Renxun disse que isso é como uma "versão moderna do Folding@home". O Folding@home fez contribuições reais no campo da simulação molecular, mas não ameaçou a posição central de pesquisa e desenvolvimento das grandes empresas farmacêuticas. Essa analogia é muito precisa.
SN3 implementou o protocolo e validou a direção viável para o treinamento distribuído. Mas, do ponto de vista técnico e industrial, por trás desse desempenho apresentado, ainda existem uma série de problemas que poucas pessoas estão dispostas a discutir seriamente:
O MMLU também é uma métrica controversa na comunidade acadêmica, pois há risco de vazamento de questões e respostas de benchmarks públicos para conjuntos de treinamento. Mais importante ainda é a escolha das linhas de base comparativas: os modelos LLaMA-2-70B e LLM360 K2, aos quais o artigo se compara, são modelos antigos de 2023 a 2024, enquanto pontuações entre 65 e 70 nesse mesmo intervalo são consideradas de nível médio-inferior e inicial ao serem avaliadas em relação ao Grok e ao Doubao, e consideradas severamente atrasadas segundo o Claude. Se colocado em listas dinâmicas atualizadas ou em benchmarks novos com design resistente à contaminação, a conclusão poderia ser mais honesta.
Mais importante ainda, os dados de alta qualidade que determinam o limite de capacidade do modelo — dados de conversas, código, derivações matemáticas e literatura científica — provavelmente estão nas mãos de grandes empresas, editoras e bancos de dados acadêmicos. A computação se democratizou, mas o lado dos dados permanece uma estrutura oligopolística, e essa contradição nunca foi discutida.
Em relação à segurança, a participação sem permissão significa que você não sabe quem está por trás desses mais de 70 nós nem quais dados eles estão usando para treinar. A Gauntlet pode filtrar gradientes claramente anômalos, mas não consegue prevenir envenenamento sutil de dados — se um nó treinar sistematicamente algumas rodadas adicionais em direção a um tipo específico de conteúdo prejudicial, as alterações no gradiente serão suficientemente sutis para passar na triagem por pontuação de perda, mas causarão um deslocamento acumulativo no comportamento do modelo. A questão final é: em cenários de alta conformidade e segurança, como finanças, saúde e direito, quais riscos são impostos ao usar um modelo treinado por poucos nós anônimos com fontes de dados incompletas ou não rastreáveis?
Há ainda um problema estrutural que merece ser dito diretamente: o Covenant-72B é aberto sob a licença Apache 2.0 e não utiliza o token SN3. Possuir o token SN3 significa compartilhar os ganhos de emissão provenientes da produção contínua de novos modelos por esta subrede, e não quaisquer ganhos diretos gerados pelo uso do modelo. Essa cadeia de valor depende da produção contínua de treinamentos e do funcionamento saudável do mecanismo de emissão da rede Bittensor como um todo. Se, no futuro, os treinamentos pararem ou os novos resultados de treinamento não atingirem a qualidade esperada, a lógica de avaliação do token será comprometida.
Listar essas questões não é para negar o significado do Covenant-72B. O fato de que ele provou que algo antes considerado impossível pode ser feito não desaparecerá. Mas fazer algo e o que isso significa são duas coisas diferentes.
O token SN3 subiu 440% no último mês. Essa distância pode não ser apenas especulação, mas sim o fato de que as narrativas sempre avançam mais rápido do que a realidade. Se essa lacuna será preenchida pela realidade ou absorvida pela correção do mercado, dependerá do que a equipe da Covenant AI realmente entregar nos próximos passos.
É importante notar que a Grayscale apresentou o pedido de ETF de TAO em janeiro de 2026, indicando um sinal de entrada de capital institucional neste segmento. Além disso, em dezembro de 2025, o Bittensor reduziu pela metade a emissão diária de TAO, e a retração estrutural na oferta ainda está em curso.
Link de referência:
https://arxiv.org/pdf/2603.08163
https://importai.substack.com/p/importai-449-llms-training-other
https://docs.tplr.ai/
https://systems-analysis.ru/int/MMLU_Benchmark_%E2%80%94_MMLU_%E5%9F%BA%E5%87%86%E6%B5%8B%E8%AF%95