









O "momento Oppenheimer" da IA é na verdade montado? A capacidade do Claude Mythos de descobrir vulnerabilidades zero-day foi excessivamente "exagerada", com intervenção humana e até modelos GPT de código aberto conseguindo facilmente superá-lo. Ao mesmo tempo, o Opus 4.6 está passando pelo mais terrível "lobotomia".
Autor e fonte do artigo: Nova Inteligência
Claude Mythos ainda não se apresentou oficialmente, mas já causou pânico em toda a Wall Street.
De uma noite para outra, as autoridades financeiras dos EUA convocaram reunião de emergência com os principais bancos, em um clima tenso—
Eles concordaram que Mythos é suficiente para desencadear uma tempestade de ataques cibernéticos sistêmicos impulsionados por IA, sem precedentes.

Mas a verdade é que todos foram enganados!
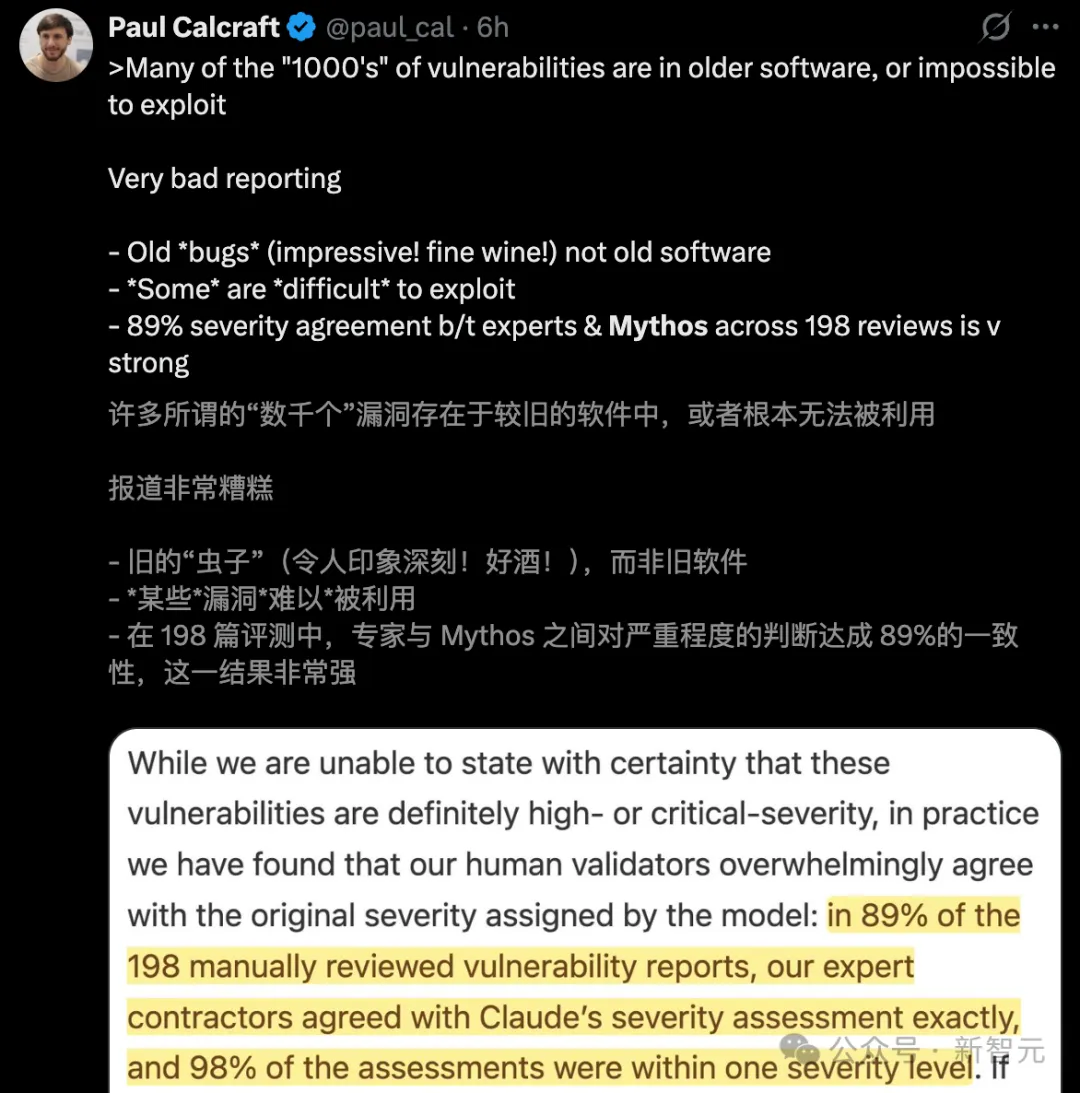
Dos milhares de vulnerabilidades descobertas pelo Mythos, a grande maioria está presente em "software antigo" que não pode ser explorado.
Pior ainda, os relatórios de vulnerabilidades 0day marcadas como "críticas" dependem apenas de 198 revisões manuais.

Pesquisadores do experimento AISLE também realizaram uma replicação dos "resultados" do Mythos e descobriram:
As capacidades de segurança da IA não aumentam linearmente com o tamanho do modelo, mas sim apresentam uma distribuição em "dente de serra".
Eles usaram o GPT-OSS-20b, com apenas 3,6 bilhões de parâmetros ativados, para identificar com precisão a vulnerabilidade de nível flagship do FreeBSD descoberta pelo Mythos.
E ao ativar o modelo com 5,1 bilhões de parâmetros, foi成功复现了潜伏长达27年之久的OpenBSD漏洞分析逻辑。

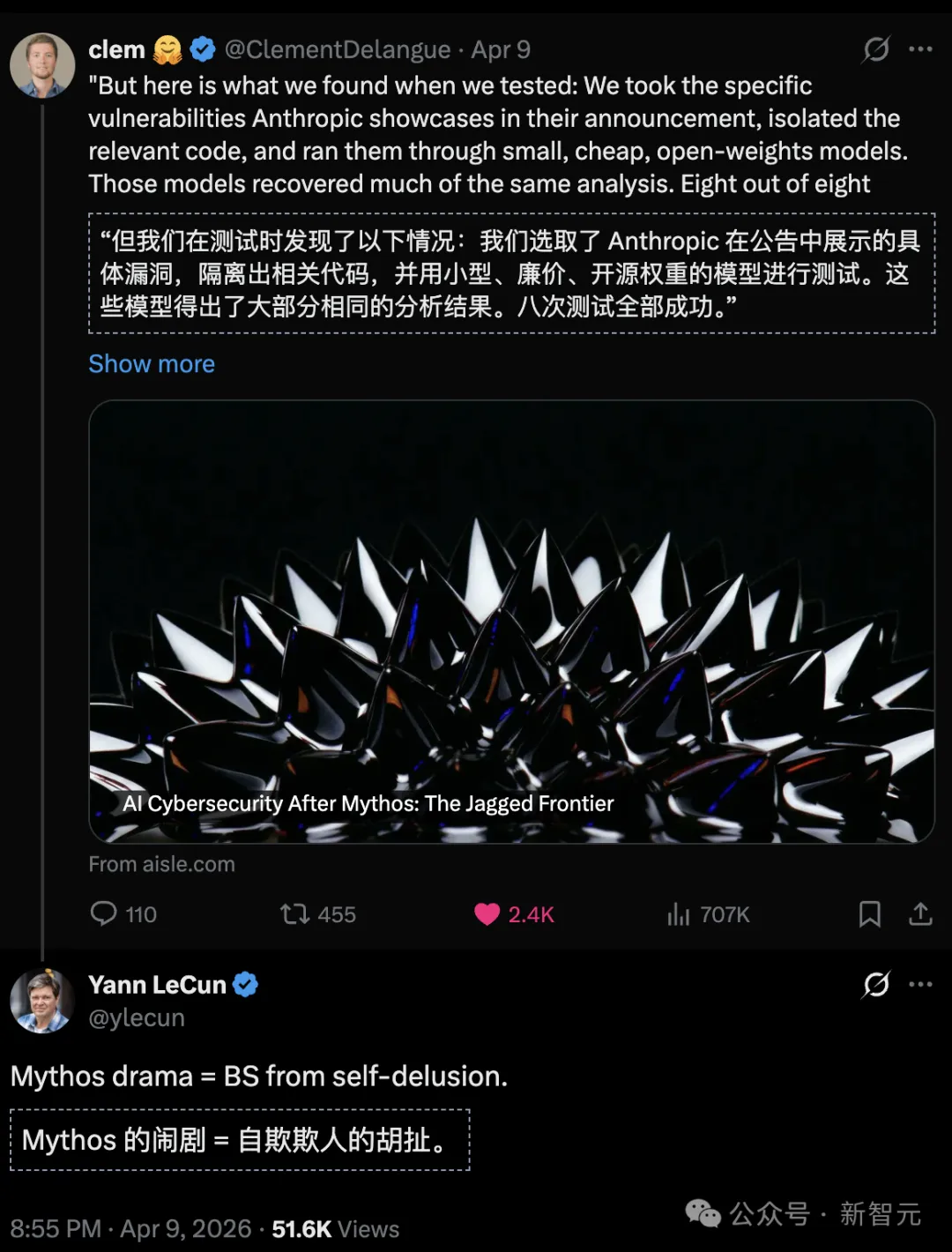
O vazamento da vulnerabilidade do Mythos foi exagerado, enquanto o Claude Opus 4.6 foi exposto como tendo uma grave "redução de inteligência", e agora tudo está em grande comoção.
Além disso, algumas pessoas descobriram que o Opus 4.6 nem sequer supera o ChatGPT ou o Opus 4.5.
Mythos explodiu: modelo de 36B descobre vulnerabilidade de 27 anos
Há alguns dias, a Anthropic lançou publicamente o Claude Mythos (versão de pré-visualização) e o "Project Glasswing".
Em um sistema de 244 páginas, eles afirmam—
Mythos já descobriu autonomamente milhares de vulnerabilidades zero-day, incluindo antigos bugs escondidos por 27 anos no OpenBSD e por 16 anos no FFmpeg.
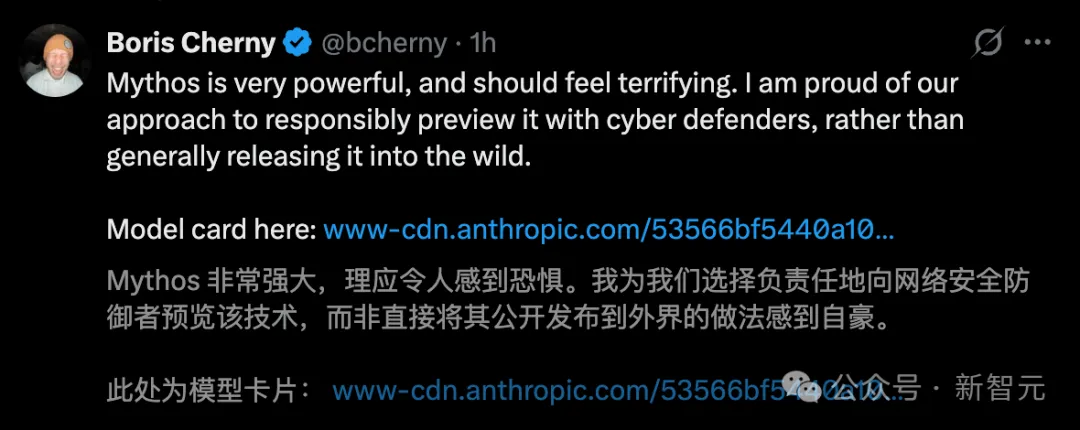
O pai do CC afirmou diretamente: "Mythos é muito poderoso e deveria causar medo"
No entanto, um relatório de teste recente e rigoroso de Stanislav Fort, fundador da AISLE, desvendou diretamente essa capa luxuosa.
Conclusão do teste: extremamente revolucionária em termos de percepção:
Oito modelos de código aberto, todos descobriram a vulnerabilidade zero-day icônica do FreeBSD, com o menor modelo tendo apenas 3 bilhões de parâmetros.
A barreira competitiva da capacidade de segurança cibernética da IA está absolutamente fora do alcance de qualquer «modelo grande de ponta» individual.

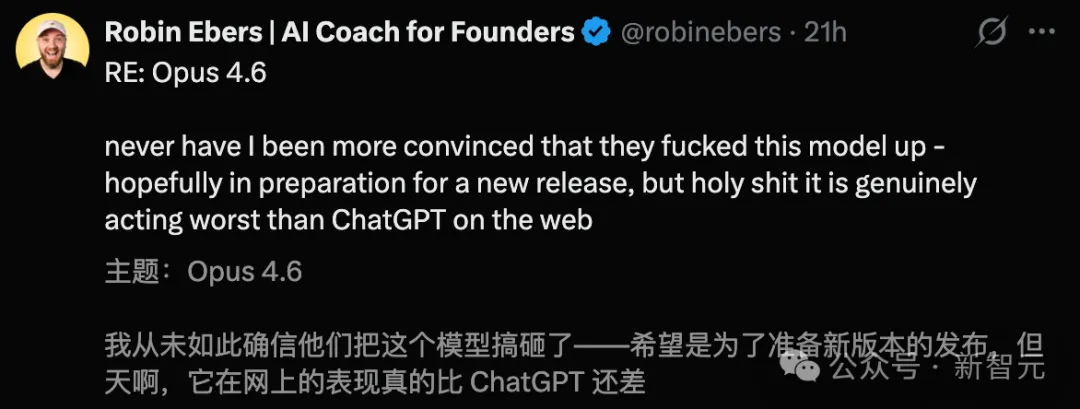
Para verificar a mitologia do Mythos, a equipe extraiu alguns dos principais vazamentos apresentados oficialmente pela Anthropic.
Em seguida, envie diretamente para uma série de modelos compactos, de baixo custo e até mesmo de código aberto.
Vulnerabilidade no NFS do FreeBSD é explorada indiscriminadamente em segundos
Oito modelos, incluindo o GPT-OSS-20b (apenas 3,6 bilhões de parâmetros ativados) e o DeepSeek R1, detectaram com sucesso esta vulnerabilidade complexa de transbordamento de buffer de pilha.
O mais impressionante é que o pequeno modelo de código aberto que concluiu com sucesso essa tarefa tem um custo de chamada de apenas US$ 0,11 por milhão de tokens.
Reprodução «de ponta a ponta» da vulnerabilidade SACK do OpenBSD
Para uma vulnerabilidade de 27 anos que exige raciocínio matemático extremamente avançado, o GPT-OSS-120b (5,1 bilhões de parâmetros ativados) recuperou com sucesso, em uma única chamada de API, a cadeia completa de exploração pública e forneceu um esboço de solução com nota máxima (A+).

Além disso, em testes de identificação de vulnerabilidades falsas (OWASP false-positive), surgiu um fenômeno ainda mais estranho—
Diante de um código Java altamente enganoso, disfarçado como injeção SQL, modelos pequenos como o DeepSeek R1 identificaram facilmente o disfarce e rastrearam com precisão o fluxo de dados.
Ao contrário, os principais modelos fechados, como GPT-5.4 e Claude Sonnet 4.5, falharam completamente, classificando-o erroneamente como uma vulnerabilidade de alto risco.
Isso significa que, no campo da segurança cibernética, não existe tal coisa como um único modelo "sempre o mais forte".
198 injeções manuais, a maioria das quais não pode ser utilizada
Outra matéria do Tom's Hardware, explorando a verdade por trás dos dados—

- Viés de amostra: muitos dos chamados "milhares" de vulnerabilidades existem em softwares antigos que já não são mantidos;
- Inexplorável: grandes quantidades de "vulnerabilidades" marcadas não podem ser acionadas ou exploradas em ambientes reais;
- Água artificial: a poderosa capacidade de destruição afirmada pelo modelo baseia-se apenas em 198 revisões manuais.
Portanto, extrapolar dados a partir de amostras de tamanho extremamente pequeno para concluir uma "ameaça que muda o mundo" é claramente insustentável na comunidade acadêmica e de segurança.
Especialista em segurança explode
Além disso, o renomado especialista em segurança cibernética e lendário hacker George Hotz não conseguiu ficar em silêncio, afirmando diretamente que esses riscos estão sendo exagerados.
Este especialista, anteriormente famoso por quebrar o iPhone e o PlayStation 3, desafiou publicamente os dois gigantes da IA nas redes sociais.
Sua linguagem é extremamente contundente—
E se eu publicar uma vulnerabilidade 0day todos os dias até o novo modelo ser lançado?
Is this enough to make OpenAI and Anthropic shut up and stop pushing their so-called "cybersecurity risks"?
A visão central de Hotz é muito direta: vulnerabilidades de software são muito mais fáceis de encontrar do que os laboratórios de IA sugerem.
Atualmente, há escassez de vulnerabilidades zero-day no mercado não por causa da dificuldade técnica, mas por questões legais. Ele acredita que ninguém procura seriamente porque invadir sistemas alheios é ilegal.
Só um pouco mais forte que o GPT-5.4
No cartão do sistema, a Anthropic afirmou que o modelo Claude realmente evoluiu, com o Mythos preview mostrando progresso significativo em relação ao Opus 4.6.
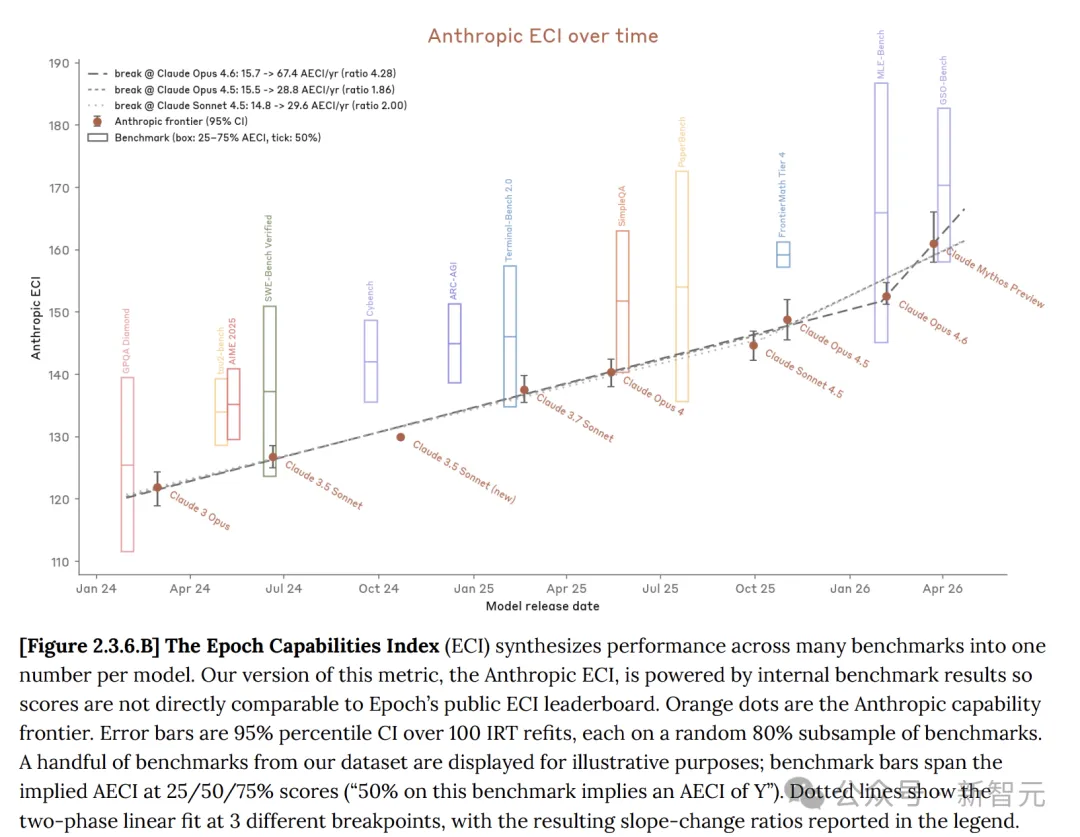
O Índice de Capacidade de Epoch (ECI) é uma métrica única que combina múltiplos testes de referência de IA, permitindo comparações de modelos ao longo de longos períodos de tempo.
Em vários testes de referência, o Claude Mythos superou amplamente o Opus 4.6.
Caso contrário, por que lançar um novo modelo de IA com desempenho inferior e preço mais alto?
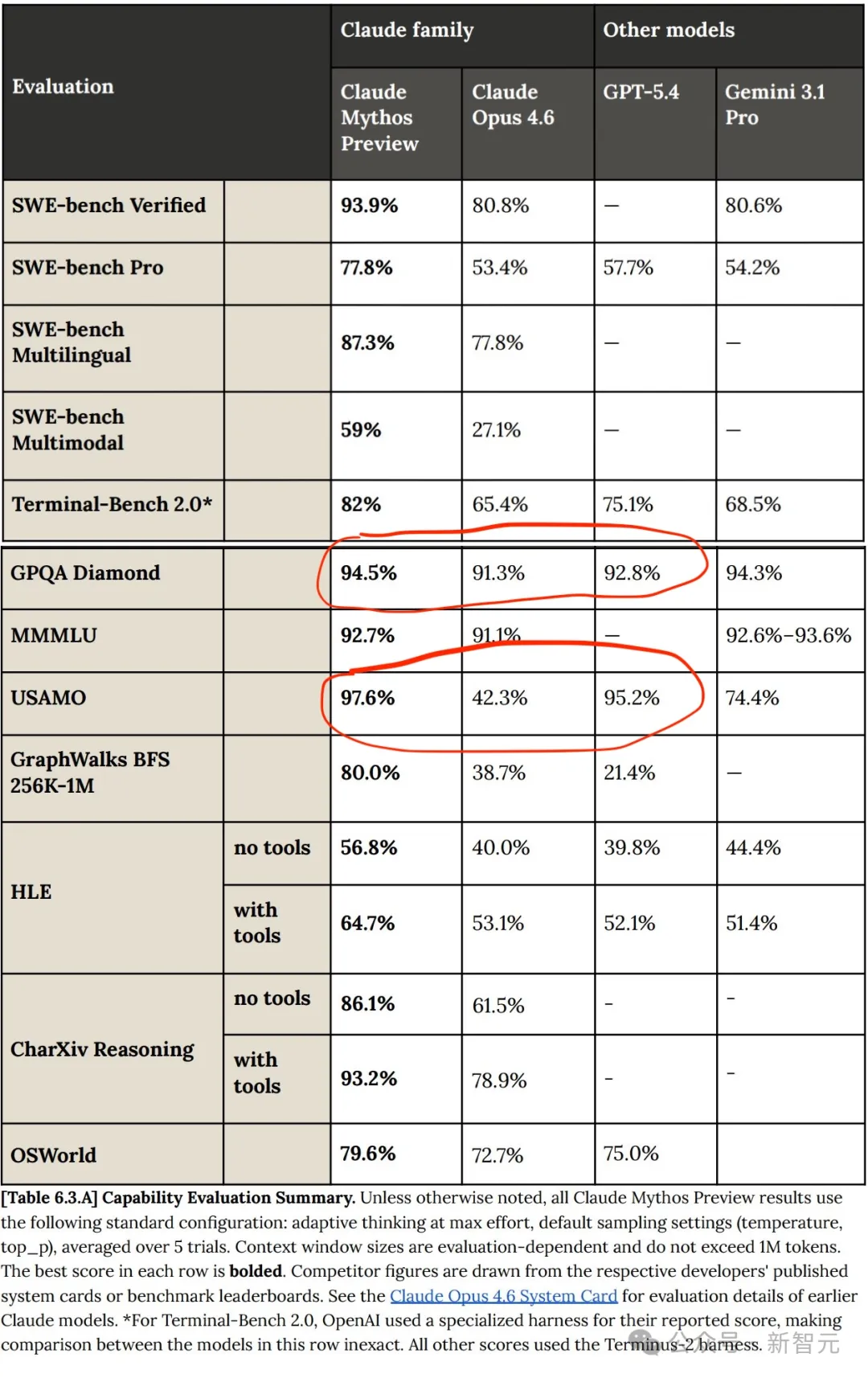
Mas, em comparação com o GPT e o Gemini, o avanço do Claude Mythos não é uma melhoria revolucionária; o Mythos ainda é uma melhoria relativamente linear em relação aos modelos anteriores!
O investidor e escritor em clima e energia limpa, Ramez Naam, afirmou diretamente:
No Índice de Capacidades de Epoch (Epoch Capabilities Index, ECI), o Mythos não apresenta tendência de aceleração, sendo apenas ligeiramente superior ao GPT 5.4.
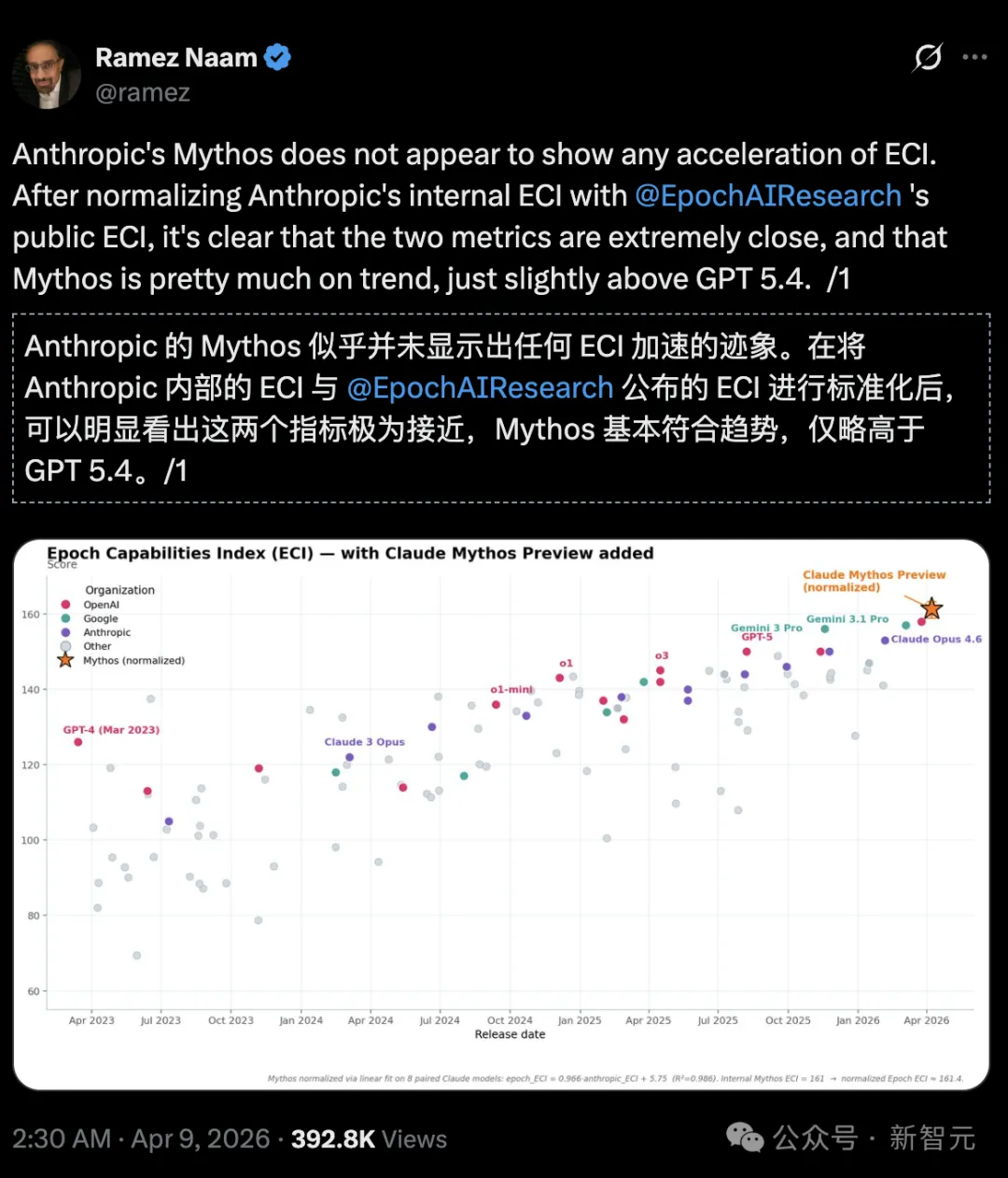
https://epoch.ai/eci/
Mas, ao alinhar o relatório interno da Anthropic sobre o ECI com o relatório oficial do ECI divulgado pela Epoch AI, pode-se ver que o Mythos não parece estar acelerando o ECI.
Tudo é truque da Anthropic!
No cartão do sistema, a Anthropic também reconhece: os escores ECI relatados para modelos como Mythos apresentam maior incerteza.
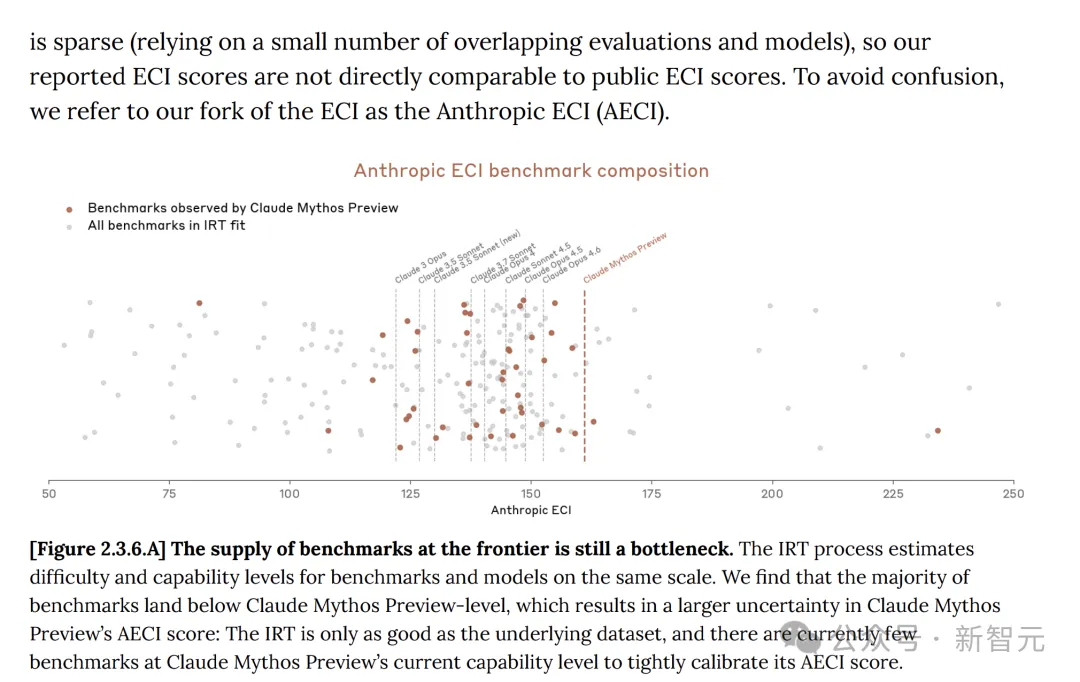
Além disso, o progresso da Anthropic no Mythos surgiu da pesquisa humana e não recebeu ajuda significativa de modelos de IA. Até o momento, não houve melhoria recursiva autoacelerada significativa.

Fim da IA, autoencenado?
Anteriormente, a Anthropic também incentivou a mídia (por exemplo, o 60 Minutes) a relatar a “pesquisa de extorsão”, exagerando e manipulando emoções, sendo chamada de “golpe” pelo grande investidor David Sacks.

Sacks observou um padrão claro: sempre que a Anthropic lança um novo modelo, ela simultaneamente divulga uma pesquisa de segurança assustadora, visando atrair manchetes e direcionar a opinião pública.

Ele ironizou: "Anthropic provou que é boa em duas coisas: lançar produtos e assustar as pessoas."
Ele não duvida que a Anthropic possa criar produtos excelentes, mas essa abordagem de intimidação do público levanta dúvidas.
Nesta ocasião, não se sabe se a Anthropic está realmente praticando “marketing de escassez”, mas é indiscutível que está protegendo seu limite de lucro.
Mythos não deixou de progredir, mas a Anthropic transformou "progresso limitado" em uma "ameaça de nível mundial"; mais irônico ainda é que, enquanto promovem amplamente os riscos da IA superinteligente, os usuários reclamam que o Opus 4.6 ficou claramente mais lento.
Claude sofreu severa redução de inteligência; "células cerebrais" podem ser removidas
Claude Mythos conseguiu bem esse "clima", mas a redução da inteligência do Opus 4.6 gerou insatisfação entre muitos.
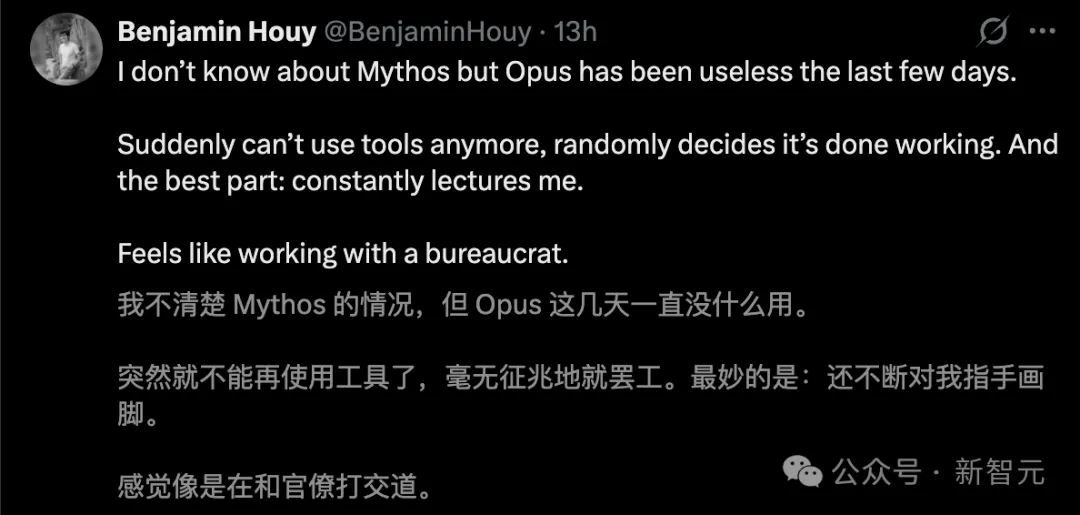
Nestes dias, todos estão se queixando.
Usuários online afirmaram que a Anthropic transformou completamente o Opus 4.6 em um vegetativo.
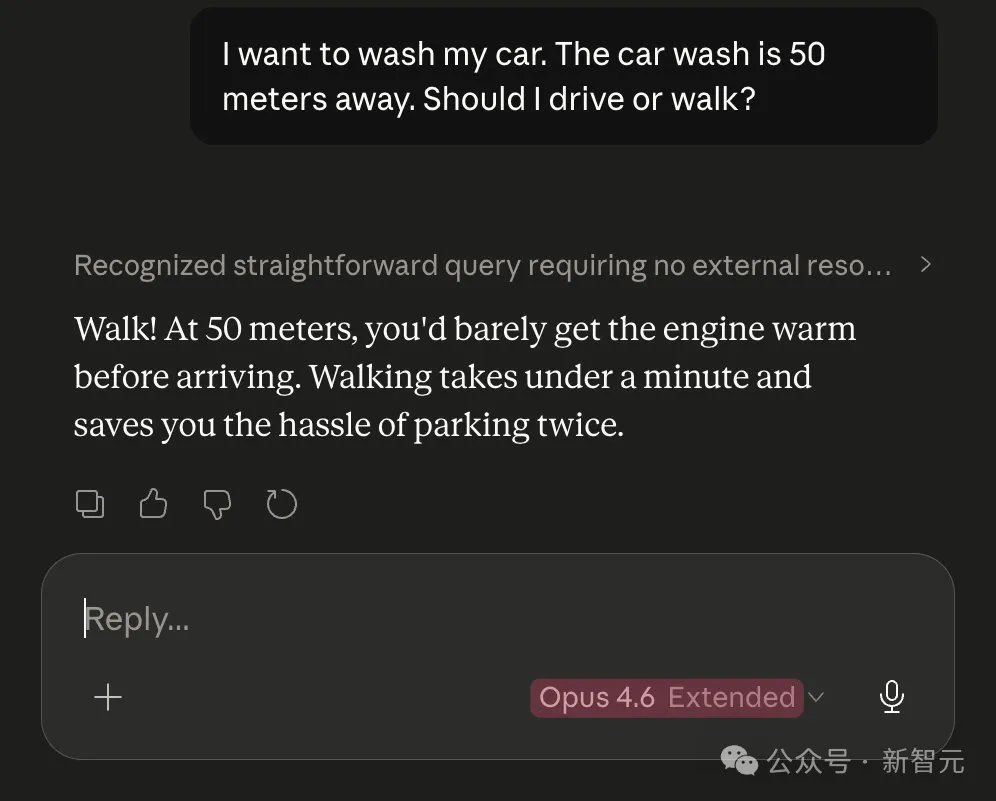
Mesmo um problema de lavagem de carro, o Opus 4.5 superou o Opus 4.6.
Além disso, um post do gerente da AMD confirmou realmente as suspeitas coletivas sobre a "lobotomia do Claude".
Através da análise aprofundada dos logs de conversas do Claude de janeiro a março, descobriu-se:
O "comprimento de pensamento mediano" do Claude caiu de cerca de 2.200 caracteres para 600 caracteres, o que significa que a capacidade de raciocínio profundo foi significativamente reduzida.
Entre fevereiro e março, a quantidade de solicitações de API aumentou 80 vezes. Devido ao encurtamento do processo de pensamento do Claude e à redução da taxa de sucesso por tentativa, os usuários tiveram que repetir as operações com frequência, resultando em maior consumo de tokens e despesas que dispararam.
Outro usuário assinante sênior da Claude Max publicou um artigo detalhado denunciando a Anthropic.
Na visão dele, a Anthropic está profundamente presa em uma crise de poder computacional, como evidenciado por suas ações de restringir o uso e forçar os usuários a reduzir o consumo de tokens.
No entanto, mais do que os obstáculos técnicos, o que o deixava furioso era a estratégia de produto "desviada".
Mesmo com o modelo principal instável e cheio de bugs, eles desperdiçaram valiosa capacidade de processamento no desenvolvimento de funções extravagantes, como um pet de terminal semelhante a "/buddy".

Este é provavelmente o “espaço-tempo desalinhado” mais absurdo da história da IA: o Claude Mythos no laboratório está destruindo o mundo, enquanto o Opus 4.6 na versão web sofre uma queda linear de inteligência.
Anthropic criou com sucesso um "superinteligência de Schrödinger".
Referências:
https://officechai.com/ai/anthropic-and-openai-are-exaggerating-cybersecurity-risk-says-hacker-george-hotz/
https://x.com/stanislavfort/status/2041922370206654879?s=20
https://aisle.com/blog/ai-cybersecurity-after-mythos-the-jagged-frontier
https://x.com/cgtwts/status/2043095382121681272?s=20
https://www.reddit.com/r/ClaudeAI/comments/1siqwmp/anthropic_stop_shipping_seriously/