









Enquanto pessoas comuns ainda estudam as "melhores fórmulas de prompt", os laboratórios de ponta da Vale do Silício já transformaram a infraestrutura de IA em uma linha de produção
Autor e fonte do artigo: Nova Inteligência
Você ainda está repetindo prompts na caixa de bate-papo do ChatGPT?
Recentemente, um usuário do X postou um tweet começando com um grito de surpresa: O modelo do projeto Claude Code, usado secretamente por grandes empresas, foi vazado!
Isso já não é escrever prompts. É infraestrutura de engenharia de IA.

Todo o conjunto de estratégias gira em torno de um arquivo chamado «CLAUDE.md», cujos princípios fundamentais são apenas três:
Cada vez que Claude erra → você adiciona uma regra; cada vez que você se repete → você adiciona um fluxo de trabalho; cada vez que ocorre um bug → você adiciona uma barreira de proteção.

Fazer isso é transformar a experiência do projeto em um contexto permanente e restrições automatizadas que serão lidas a cada inicialização.
Toda a arquitetura, como a estrutura de cargos de uma empresa de IA: CLAUDE.md é o manual de boas-vindas, skills/ são os SOPs de trabalho, hooks/ é o departamento de conformidade, docs/ são os estatutos sociais, tools/ é a equipe de logística e src/ é o verdadeiro departamento operacional que produz os resultados.

Você não está mais conversando com uma IA, mas sim construindo uma IA que entende seu repositório de código.
A parte mais louca é que você só precisa configurar uma vez; o Claude revisará automaticamente o código, reestruturará conforme instruído, aplicará regras de arquitetura, escreverá notas de lançamento, executará fluxos de trabalho a partir de habilidades e lembrará erros anteriores.
E ficará mais inteligente com o uso.
A maioria das pessoas abre o ChatGPT, escreve um prompt, copia e cola, repetidamente; mas com este método, você só precisa abrir o terminal e executar um código de skill já entregue.
É como ter uma equipe de colegas de IA criada no seu próprio repositório de código.
Por trás deste tweet, há um pequeno sinal de que esta era está silenciosamente chegando ao fim, e a maioria das pessoas ainda não percebeu.
Uma "captura de tela vazada" que não é realmente uma vazamento revela uma verdade
@ai_rohitt mostrou esta captura de tela, que é o padrão oficial recomendado pela documentação da Anthropic para o Claude Code.
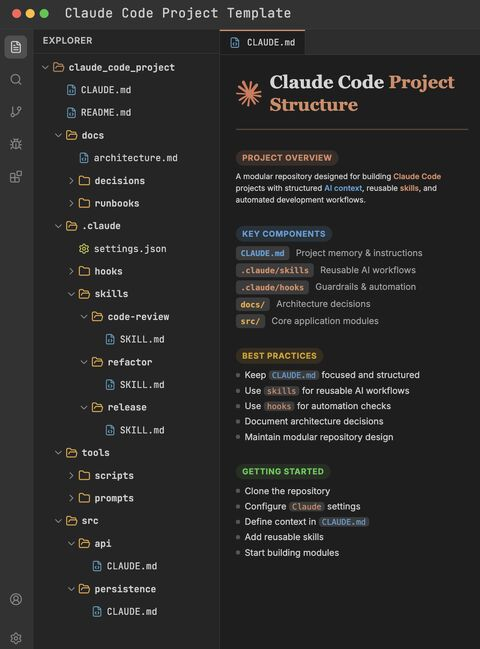
CLAUDE.md é o arquivo de memória do projeto lido automaticamente pelo Claude Code no início de cada sessão.
.claude/skills/ e .claude/hooks/ são mecanismos de extensão oficialmente suportados.
Essas são práticas públicas já discutidas pela comunidade por vários meses, e não um "modelo interno" roubado por ninguém.
Mas o fato de ele ter sido compartilhado ativamente por alguns desenvolvedores experientes indica que ele recebeu o reconhecimento de desenvolvedores que usam o Claude diariamente.
Uma boa parte das pessoas só percebeu nos últimos dias que ele pode ser usado assim.
E a equipe de alto nível da Vale do Silício já transformou isso em uma linha de produção.
O primeiro exemplo é a equipe OpenAI Frontier.
Nos experimentos da equipe Frontier divulgados oficialmente pela OpenAI, um beta interno iniciado a partir de um repositório vazio gerou aproximadamente 1 milhão de linhas de código e cerca de 1.500 PR em cerca de cinco meses pelo Codex; a equipe expandiu de 3 para 7 membros, sem codificação direta por humanos.
Ryan Lopopolo, líder da equipe, mencionou posteriormente em entrevista que este fluxo de trabalho já está próximo da forma limite de "0 código manual, 0 revisão manual".
Ele acredita que, em vez de economizar tokens, é melhor aproveitar a capacidade altamente concorrente e o custo extremamente baixo do modelo para substituir a atenção sincronizada limitada e cara dos seres humanos.
O segundo exemplo é o sistema de agente de código automatizado interno da Stripe, chamado Minions.
Os Minions dentro da Stripe geram e impulsionam mais de 1.300 PRs por semana, todos os códigos gerados inteiramente por IA, mas ainda revisados por humanos.
Aqui há mais um conjunto de dados: 1,6% vs 98,4%, proveniente de um artigo publicado pelo VILA-Lab da Universidade Mohamed bin Zayed para IA.

https://arxiv.org/pdf/2604.14228
Pesquisadores analisaram sistematicamente 512.000 linhas de código-fonte TypeScript da versão Claude Code v2.1.88 e concluíram que apenas 1,6% é lógica de decisão da IA, enquanto os 98,4% restantes são infraestrutura de engenharia determinística.
Especificamente, são quatro categorias: gateway de permissões, gerenciamento de contexto, roteamento de ferramentas e recuperação de erros.
Esses números não significam que o modelo contribui apenas com 1,6% de capacidade, mas sim que, como produto, o Claude Code tem grande parte de sua complexidade não no modelo em si, mas em infraestruturas de engenharia determinística, como permissões, contexto, roteamento de ferramentas e mecanismos de recuperação.
A estrutura CLAUDE.md/skills/hooks naquela imagem é uma “infraestrutura básica para iniciantes” que qualquer desenvolvedor comum pode montar; ela segue o mesmo paradigma das arquiteturas de produção da OpenAI e da Stripe, apenas em escala muito menor.
Os segredos expostos do CLAUDE.md
Nos últimos três anos, todos perguntavam: “Quando o GPT ficará mais inteligente?” e “Quando sairá a nova versão do Claude?”
Mas as equipes que realmente implementaram programação com IA em produção provavelmente não se preocupam com isso, e sim em como fazer com que a IA se lembre dos erros cometidos anteriormente, como fazer com que a IA verifique as restrições de arquitetura do projeto antes de agir e como garantir que, quando a IA errar, ela seja impedida pelas ferramentas.
CLAUDE.md é exatamente o veículo que sustenta tudo isso.
A definição oficial da Anthropic é apenas uma frase:
Um arquivo markdown, colocado no diretório raiz do projeto, que o Claude Code lê automaticamente no início de cada sessão.

https://code.claude.com/docs/en/memory
Sounds simple, but it's the several layers built around it that make it truly impressive.
CLAUDE.md é o cérebro do projeto.
Decisões de arquitetura, convenções de nomenclatura, requisitos de teste, todos os erros repetidos — tudo está aqui. É o "manual do funcionário" que a IA vê primeiro ao iniciar.
.claude/skills/ são fluxos de trabalho reutilizáveis.
Boris Cherny, criador do Claude Code, enfatizou repetidamente na comunidade: "Se você fizer algo mais de uma vez por dia, transforme-o em uma skill ou command."
Uma skill é um método executável. Revisão de código, geração de mensagens de commit e escrita de notas de lançamento não devem ser tarefas que exigem digitação manual de prompts todos os dias; devem ser resolvidas com apenas uma chamada de skill.
.claude/hooks/ é um sistema de proteção automática.
Esta é a parte mais crítica. Não depende do AI julgar por si só; o código determinístico impede o AI antes que ele erre. É por isso que podemos permitir que o AI opere "sem supervisão", pois os limites de erro são bloqueados pelos hooks.
docs/decisions/ são registros de decisões de arquitetura.
Faça com que a IA não apenas saiba o que o código é, mas também por que ele é assim.
Este é o item mais facilmente ignorado, mas também o maior ponto de alavancagem para a colaboração com IA.
tools/ e src/ são camadas de execução.
O que realmente merece atenção nessa arquitetura não é um desenvolvedor ter criado um diretório bonito, mas sim o fato de que cada vez mais equipes independentes estão convergindo para a mesma direção: colocar modelos dentro de um sistema composto por contexto, ferramentas, permissões, avaliação e ciclos de feedback.
Já é possível ver muitos projetos semelhantes no GitHub:
O awesome-claude-code-toolkit de rohitg00, o claude-code-infrastructure-showcase de diet103 e o everything-claude-code de affaan-m estão todos construindo um ambiente de engenharia para o Claude Code em torno de componentes como agents, skills, hooks, rules e MCP configs.
Isso indica que um fluxo de trabalho de programação com IA verdadeiramente maduro não depende apenas de um modelo mais poderoso nem apenas de um prompt mais longo, mas sim de integrar o modelo em um sistema de engenharia reutilizável, controlável, recuperável e auditável.
Quanto à estrutura de diretórios específica, as implementações variam entre si.
Experiência limite do laboratório OpenAI
Em 11 de fevereiro de 2026, o blog oficial da OpenAI publicou um artigo: “Harness engineering: leveraging Codex in an agent-first world”.

https://openai.com/index/harness-engineering/
A Anthropic reestruturou a abordagem do Claude Code em torno desse conceito; o site de Martin Fowler o resumiu em uma fórmula: «Agente=Modelo+Enquadramento.»
A palavra "harness" vem da equitação. Refere-se ao conjunto completo de arreios de um cavalo: rédeas, freio, selim e cabresto.
Um cavalo pode correr rápido e com força, mas ele mesmo não sabe para onde ir: o conjunto de arreios determina sua direção.
Analogia à programação com IA: o modelo tem uma capacidade muito forte, mas não sabe para onde ir em seu repositório de código. O Harness é o volante, os freios e o navegador que você cria para ele.
O experimento da equipe Frontier da OpenAI, com "1 milhão de linhas sem intervenção humana", é essencialmente levar o Harness ao extremo.
Suas práticas de engenharia-chave incluem os seguintes itens.
Restrição forte da arquitetura em camadas.
Da Types ao Config, ao Repo, ao Service, ao Runtime e à UI, as dependências fluem unidirecionalmente e são obrigatoriamente aplicadas pelo linter no nível CI. Se o agente escrever código que viole a relação de camadas, a compilação falhará imediatamente.
As mensagens de erro do linter são instruções de correção em si mesmas, e este é o detalhe mais contra-intuitivo.
Os erros de lint de projetos comuns são "violation detected", destinados a serem lidos por humanos; os erros de lint da OpenAI Frontier são "use logger.info({event: 'name', …data}) instead of console.log", instruções diretas destinadas a Agentes, que podem ser lidas e corrigidas diretamente.
O documento serve como fonte única de verdade. Todos os diagramas de arquitetura, planos de execução e especificações de design estão no diretório docs/ dentro do repositório. O agente não precisa de nenhum banco de dados externo; tudo está no repositório.
Quão eficaz é este conjunto de coisas?
O modelo não foi alterado, mas o LangChain ajustou o harness, incluindo prompts do sistema, ferramentas, middleware e modo de raciocínio, elevando finalmente a pontuação do Terminal Bench 2.0 de 52,8 para 66,5.
O que você pode fazer hoje
Criar um cérebro para IA
A questão volta ao desenvolvedor comum: se o paradigma já mudou, o que um engenheiro comum pode fazer hoje?
Primeiro, crie um arquivo CLAUDE.md no diretório raiz do seu projeto mais importante.
Não precisa ser perfeito nem longo. Escreva as regras de arquitetura da sua equipe, convenções de nomeação, requisitos de teste e os erros recorrentes — é possível escrever uma versão funcional em 10 minutos.
Na próxima vez que a IA errar, não corrija manualmente — em vez disso, pergunte a si mesmo: o que está faltando no CLAUDE.md?
A segunda coisa é transformar as tarefas repetidas diariamente em habilidades.
Observe a frase famosa de Boris Cherny: "Se você fizer algo mais de uma vez por dia, transforme-o em uma habilidade ou comando."
Revisão de código, geração de commit message, escrita de notas de lançamento, correção de bugs repetitivos — esses devem ser skills, não algo que exija digitação manual de prompts todos os dias.
Terceiro, adicione um hook nos lugares onde é fácil cair em armadilhas.
O Hook é a parte mais alavancada dos 98,4%. Ele não depende da IA para se tornar inteligente; depende de código determinístico para execução de verificações obrigatórias. É o processo de traduzir o julgamento dos engenheiros humanos em restrições legíveis por máquinas.
O ponto central deste assunto não é escrever código, mas sim escrever regras.
A frase de Karpathy compartilhada amplamente no Twitter em janeiro deste ano: "Mudei de 80% de código escrito manualmente para 80% entregue aos Agentes."
Nos próximos cinco anos, a curva de habilidades dos engenheiros está passando de “quantas linhas de código consigo escrever” para “quão rigoroso posso tornar o ambiente de trabalho para a IA”.
As tarefas de programação estão sendo assumidas por Agentes.
Mas projetar o mundo que permite que o agente escreva bom código ainda é trabalho humano. E é mais difícil, mais importante e mais interessante do que antes.