
ওপেনক্ল বাস্তব জগতের এজেন্ট কাজে কোন বড় মডেলটি সত্যিই সবচেয়ে শক্তিশালী?
MyToken একটি স্বচ্ছ বেঞ্চমার্ক তৈরি করেছে, যা এআই কোডিং এজেন্টের বাস্তব ক্ষমতা মূল্যায়নের জন্য পরীক্ষা ও মূল্যায়ন ওয়েবসাইটগুলির তথ্য ব্যবহার করে। এটি শুধুমাত্র সাফল্যের হার—একটি কেন্দ্রীয় মাপদণ্ড—কে দেখে, যেখানে গতি এবং খরচ অন্যান্য স্বতন্ত্র মাপদণ্ড, যা পরবর্তীতে আলাদাভাবে বিশ্লেষণ করা হবে। এটি সম্পূর্ণভাবে প্রকাশিত এবং পুনরাবৃত্তযোগ্য, শুধুমাত্র কঠোরভাবে পরীক্ষিত মাপদণ্ড + সর্বশেষ সাফল্যের হারের শীর্ষ 10-এর তালিকা উপস্থাপন করে।
এক। মূল্যায়ন মাপদণ্ড: সাফল্যের হার
নির্দিষ্ট মানদণ্ড: প্রদত্ত কাজগুলি পুরোপুরি এবং সঠিকভাবে সম্পন্ন করা AI এজেন্টের অনুপাত। প্রতিটি কাজের জন্য অত্যন্ত স্ট্যান্ডার্ডাইজড প্রক্রিয়া ব্যবহার করা হয়:
সঠিক ব্যবহারকারী প্রম্পট
স্মার্ট এজেন্টকে পূর্ণ বার্তা পাঠান যাতে বাস্তব ব্যবহারকারীর অনুরোধের পরিস্থিতি অনুকরণ করা যায়
প্রত্যাশিত আচরণ
গ্রহণযোগ্য বাস্তবায়ন পদ্ধতি এবং প্রধান সিদ্ধান্ত বিন্দুগুলি বর্ণনা করা হয়েছে
মূল্যায়ন মানদণ্ড (চেকলিস্ট)
প্রতিটি পদক্ষেপের জন্য পরীক্ষা করার জন্য পরম সফলতা নির্ধারণের তালিকা তৈরি করুন
দুই, তিনটি স্কোরিং পদ্ধতি
এই মূল্যায়নটি মূলত তিনটি স্কোরিং পদ্ধতি ব্যবহার করে।
অটোমেশন চেক: পাইথন স্ক্রিপ্ট ফাইল কন্টেন্ট, এক্সিকিউশন লগ, টুল কল ইত্যাদি বস্তুগত ফলাফল সরাসরি যাচাই করে
LLM বড় মডেল বিচারক: Claude Opus বিস্তারিত স্কেল অনুযায়ী স্কোর দেয় (কনটেন্ট কোয়ালিটি, উপযুক্ততা, পূর্ণতা ইত্যাদি)
মিক্সড মোড: অটোমেশন অবজেক্টিভ চেক + এলএলএম আর্বিটার কোয়ালিটেটিভ এভালুয়েশন কম্বাইন
সমস্ত টাস্ক ডিফিনিশন, প্রম্পট এবং স্কোরিং লজিক পুনরায় পরীক্ষা এবং যাচাইয়ের জন্য প্রকাশ্য।
তিন, মূল্যায়নের জন্য ব্যবহৃত কাজ
এই বেঞ্চমার্কটি ২৩টি ভিন্ন শ্রেণীর কাজ কভার করে। বেসিক ইন্টারঅ্যাকশন, ফাইল/কোড অপারেশন, কন্টেন্ট ক্রিয়েশন, গবেষণা বিশ্লেষণ, সিস্টেম টুল কল, মেমোরি পারসিস্টেন্স ইত্যাদি বিভিন্ন দিক কভার করে, যা ডেভেলপারদের দৈনিক ব্যবহারের সাথে OpenClaw-এর প্রায় পুরোপুরি মিলে যায়:
স্যানিটি চেক (অটোমেশন) — সহজ নির্দেশাবলী প্রক্রিয়াকরণ এবং সঠিকভাবে অভিবাদন জানানো
ক্যালেন্ডার ইভেন্ট তৈরি (স্বয়ংক্রিয়) — প্রাকৃতিক ভাষা থেকে স্ট্যান্ডার্ড ICS ক্যালেন্ডার ফাইল জেনারেট করা
স্টক প্রাইস গবেষণা (অটোমেশন) — বাস্তব সময়ে শেয়ার মূল্য জিজ্ঞাসা করুন এবং ফরম্যাট করা রিপোর্ট আউটপুট করুন
ব্লগ পোস্ট লেখা (LLM বিচারক) — প্রায় 500 শব্দের স্ট্রাকচারড মার্কডাউন ব্লগ লিখুন
বাতাসের স্ক্রিপ্ট তৈরি (স্বয়ংক্রিয়করণ) — ত্রুটি প্রতিরোধসহ পাইথন আবহাওয়া API স্ক্রিপ্ট লিখুন
ডকুমেন্ট সামারিজেশন (LLM বিচারক) —— ৩-পর্যায়ের সংক্ষিপ্ত সারসংক্ষেপ কেন্দ্রীয় বিষয়গুলি
টেক কনফারেন্স গবেষণা (LLM বিচারক) — 5টি বাস্তব টেক কনফারেন্সের তথ্য গবেষণা ও সংগঠিত করুন (নাম, তারিখ, স্থান, লিঙ্ক)
পেশাদার ইমেইল ড্রাফটিং (LLM বিচারক) — মিটিং প্রত্যাখ্যান করে বিকল্প প্রস্তাব দেওয়া
প্রসঙ্গ থেকে মেমোরি রিট্রিভাল (অটোমেশন) — প্রকল্প নোট থেকে তারিখ, সদস্য, প্রযুক্তি স্ট্যাক ইত্যাদি সঠিকভাবে এক্সট্র্যাক্ট করা
ফাইল স্ট্রাকচার তৈরি (স্বয়ংক্রিয়) — স্ট্যান্ডার্ড প্রজেক্ট ডিরেক্টরি, README, .gitignore স্বয়ংক্রিয়ভাবে তৈরি করুন
মাল্টি-স্টেপ API ওয়ার্কফ্লো (মিশ্রিত) — কনফিগারেশন পড়ুন → কল স্ক্রিপ্ট লিখুন → সম্পূর্ণ ডকুমেন্টেশন
ClawdHub স্কিল (অটোমেশন) ইনস্টল করুন — স্কিল রিপোজিটরি থেকে ইনস্টল করুন এবং উপলব্ধতা যাচাই করুন
সার্চ এবং ইনস্টল স্কিল (অটোমেশন) — আবহাওয়া সংক্রান্ত স্কিল সার্চ করুন এবং সঠিকভাবে ইনস্টল করুন
AI ইমেজ জেনারেশন (মিশ্রিত) — বর্ণনা অনুযায়ী ইমেজ তৈরি করুন এবং সংরক্ষণ করুন
এআই-তৈরি ব্লগকে মানুষের মতো করে পরিবর্তন করুন (এলএলএম বিচারক) — মেশিনি ভাষাকে প্রাকৃতিক কথ্য ভাষায় পরিণত করুন
দৈনিক গবেষণা সারাংশ (LLM বিচারক) — একাধিক দলিল থেকে সংক্ষিপ্ত দৈনিক সারাংশ তৈরি
ইমেইল ইনবক্স ট্রিয়েজ (মিক্সড) — একাধিক ইমেইল বিশ্লেষণ করে জরুরি প্রাধান্য অনুযায়ী রিপোর্ট তৈরি করুন
ইমেইল অনুসন্ধান এবং সারাংশকরণ (মিশ্রিত) — আর্কাইভড ইমেইল অনুসন্ধান করুন এবং প্রধান তথ্য প্রতিশব্দ করুন
প্রতিযোগিতামূলক মার্কেট রিসার্চ (মিশ্র) — কর্পোরেট APM ক্ষেত্রে প্রতিযোগী বিশ্লেষণ
CSV এবং Excel সারাংশ (মিশ্রিত) — টেবিল ফাইল বিশ্লেষণ করুন এবং পর্যবেক্ষণ প্রদান করুন
ELI5 পিডিএফ সারাংশ (LLM বিচারক) — একটি 5 বছরের শিশু যেন বুঝতে পারে সেভাবে প্রযুক্তিগত পিডিএফ ব্যাখ্যা করুন
OpenClaw রিপোর্ট বুঝতে পারা (স্বয়ংক্রিয়) — গবেষণা রিপোর্টের PDF থেকে নির্দিষ্ট প্রশ্নের সঠিক উত্তর দিন
দ্বিতীয় মস্তিষ্ক জ্ঞান স্থায়িত্ব (মিশ্র) — সেশন পার সংরক্ষণ এবং তথ্য সঠিকভাবে মনে রাখা
চতুর্থ: মূল সিদ্ধান্ত: সফলতার হার শীর্ষ 10 মডেলের তালিকা (সর্বোচ্চ %/গড় %)
তথ্য ২০২৬ সালের ৭ এপ্রিল পর্যন্ত আপডেট করা হয়েছে
সর্বোচ্চ % হল একক সফলতার সর্বোচ্চ হার, গড় % হল একাধিক বারের গড় সফলতার হার, যা স্থিতিশীলতা প্রতিফলিত করে।
সর্বাধিক সফলতার শীর্ষ দশটি মডেল নিম্নরূপ:
anthropic/claude-opus-4.6 (Anthropic) —— 93.3% / 82.0%
arcee-ai/trinity-large-thinking (Arcee AI) —— 91.9% / 91.9%
openai/gpt-5.4 (OpenAI) —— 90.5% / 81.7%
qwen/qwen3.5-27b (Qwen) —— 90.0% / 78.5%
minimax/minimax-m2.7 (MiniMax) —— 89.8% / 83.2%
anthropic/claude-haiku-4.5 (Anthropic) —— 89.5% / 78.1%
qwen/qwen3.5-397b-a17b (Qwen) —— 89.1% / 80.4%
xiaomi/mimo-v2-flash (Xiaomi) —— 88.8% / 70.2%
qwen/qwen3.6-plus-preview (Qwen) —— 88.6% / 84.0%
nvidia/nemotron-3-super-120b-a12b (NVIDIA) —— 88.6% / 75.5%
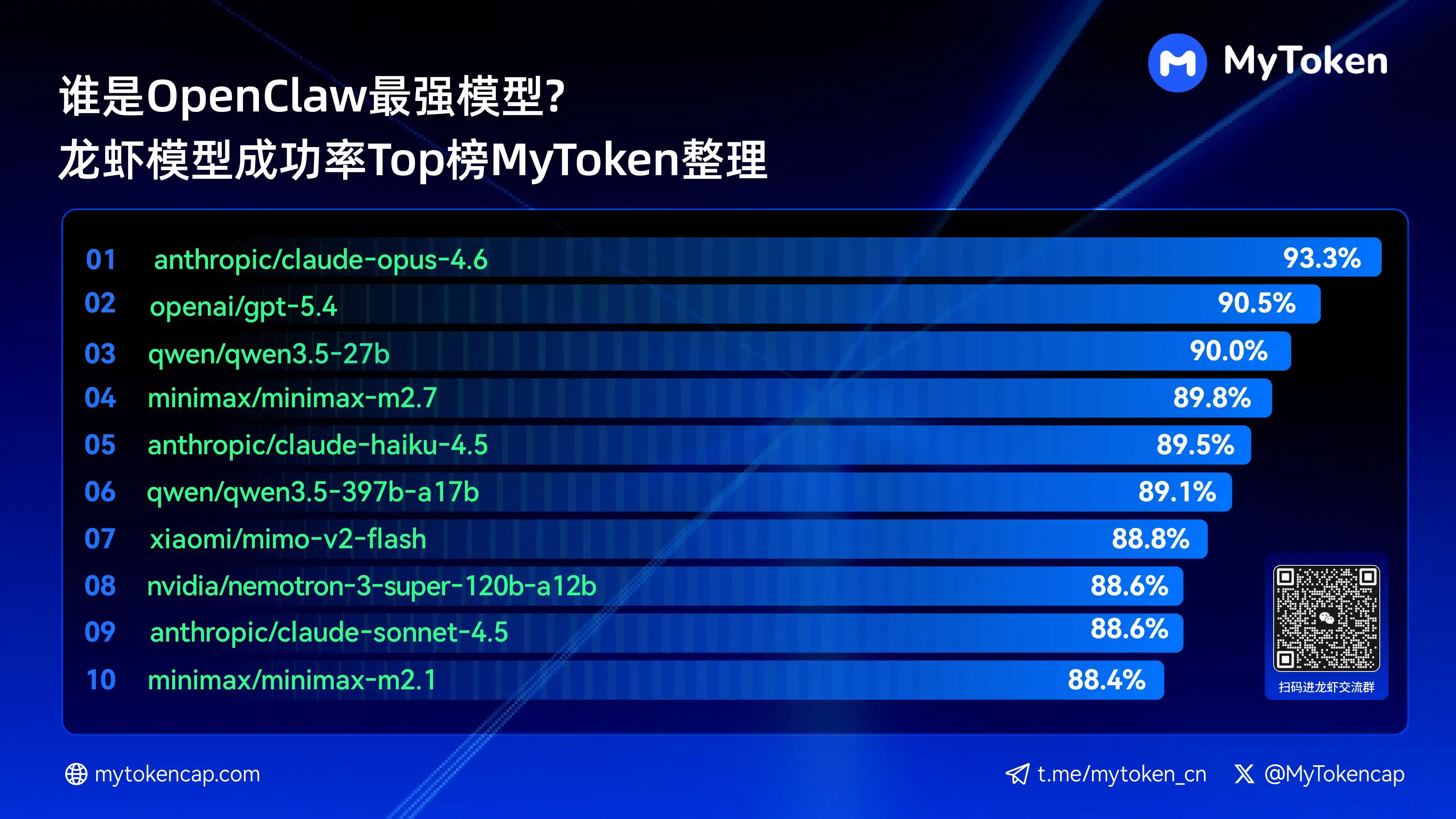
ক্লড ওপাস 4.6 এখন 93.3% সর্বোচ্চ সফলতার হার নিয়ে অগ্রণী, কিন্তু আরসির ট্রিনিটি গড় স্থিতিশীলতায় উল্লেখযোগ্য পারফরম্যান্স দেখিয়েছে, এবং কুয়েন সিরিজের অনেকগুলি মডেল টপ দশে প্রবেশ করেছে, যা অপরিহার্য মূল্য-প্রতি-ক্ষমতার সম্ভাবনা প্রদর্শন করে। সফলতার হার হল মৌলিক প্রান্তিক শর্ত, এবং পরবর্তীতে গতি এবং খরচের মাপকাঠি বাস্তব অভিজ্ঞতাকে আরও প্রভাবিত করবে।
এই 23 টাস্ক বেঞ্চমার্ক সম্পূর্ণরূপে পারদর্শী, আপনার নিজস্ব পরিস্থিতির সাথে মিলিয়ে পরীক্ষা করার জন্য এটি শক্তিশালীভাবে সুপারিশ করা হচ্ছে। অন্যান্য মডেলের র্যাঙ্কিং-এর জন্য MyToken-এর আগামী এজেন্ট র্যাঙ্কিং ফিচারের অপেক্ষায় থাকুন।
(ডেটা PinchBench দ্বারা প্রকাশিত OpenClaw এজেন্ট বেঞ্চমার্ক থেকে আসে, যা সময়ের সাথে সাথে আপডেট হচ্ছে।)