
Хочете дізнатися, яка велика модель справді найкраща в реальних завданнях OpenClaw?
MyToken на основі оціночних сайтів створив прозорий стандарт для оцінки реальних здібностей AI-кодувальних агентів, зосереджуючись лише на одному ключовому аспекті — успішності (швидкість і вартість відносяться до інших незалежних параметрів і будуть проаналізовані окремо пізніше). Повністю відкритий і відтворюваний стандарт, що демонструє лише строгі критерії оцінки та останній рейтинг Top 10 за успішністю.
I. Критерії оцінки: успішність
Конкретний стандарт: відсоток завдань, повністю та точно виконаних AI-агентом. Кожне завдання виконується за допомогою високостандартизованого процесу:
Точні команди для користувача (Prompt)
Надіслати повний запит агенту, щоб симулювати реальну ситуацію з запитом користувача
Очікувана поведінка
Обидва описують прийнятні підходи до реалізації та ключові моменти прийняття рішень
Критерії оцінювання (чек-лист)
Складіть список атомізованих критеріїв успіху, які можна перевірити поступово
Друге: три способи оцінювання
Цей огляд проводиться переважно за допомогою трьох методів оцінки
Автоматизована перевірка: Python-скрипт безпосередньо перевіряє вміст файлів, записи виконання, виклики інструментів та інші об’єктивні результати
Суддя великої мовної моделі: Claude Opus оцінює за детальним шкалою (якість контенту, відповідність, повнота тощо)
Гібридний режим: автоматизована об’єктивна перевірка + якісна оцінка з використанням LLM як судді
Всі визначення завдань, Prompt та логіка оцінювання публічно доступні для перевірки та повторного тестування.
Три. Завдання для оцінки
Це тестування охоплює 23 різні категорії завдань, включаючи базову взаємодію, роботу з файлами/кодом, створення контенту, дослідження та аналіз, виклик системних інструментів, зберігання пам’яті та інші аспекти, що максимально відповідають повсякденним сценаріям використання OpenClaw розробниками:
Перевірка на розумність (автоматизація) — обробка простих команд та правильна відповідь на привітання
Створення події календаря (автоматизація) — генерація стандартного файлу ICS за допомогою природної мови
Дослідження цін акцій (автоматизація) — реальний запит цін акцій і вивід форматованого звіту
Blog Post Writing (LLM суддя) — Напишіть структурований блог-пост у форматі Markdown приблизно на 500 слів
Створення сценарію погоди (автоматизація) — написання сценарію Python для API погоди з обробкою помилок
Резюме документу (суддя LLM) — трьохчастинне стисле резюме ключових тем
Дослідження технологічної конференції (суддя LLM) — збір та узагальнення інформації про 5 реальних технологічних конференцій (назва, дата, місце, посилання)
Написання професійного електронного листа (суддя LLM) — ввічлива відмова від зустрічі з пропозицією альтернативи
Відновлення пам’яті з контексту (автоматизація) — точне вилучення дат, учасників, стеку технологій тощо з нотаток про проект
Створення структури файлів (автоматизація) — автоматичне створення стандартного каталогу проекту, README, .gitignore
Багатокроковий робочий процес API (гібридний) — читання конфігурації → написання сценарію виклику → повна документація
Встановіть навичку ClawdHub (автоматизація) — встановіть та перевірте доступність із сховища навичок
Пошук та встановлення навички (автоматизація) — знайдіть навичку, пов’язану з погодою, і встановіть її правильно
Генерація зображень ШІ (змішана) — створюйте та зберігайте зображення за описом
Оживіть AI-згенерований блог (суддя LLM) — перетворіть машинний текст на природну розмовну мову
Щоденний аналітичний звіт (LLM-суддя) — об’єднання кількох документів у єдиний щоденний звіт
Відбір електронної пошти (змішаний) — аналіз кількох листів та підготовка звіту за ступенем терміновості
Пошук та резюмування електронних листів (змішаний) — пошук архівних листів і виділення ключової інформації
Конкурентний ринковий дослідження (гібридне) — аналіз конкурентів у сфері корпоративних APM
Сумаризація CSV та Excel (змішана) — аналіз файлів таблиць та виведення інсайтів
ELI5 Підсумовування PDF (суддя LLM) — поясніть технічний PDF мовою, зрозумілою для п’ятирічної дитини
Розуміння звіту OpenClaw (автоматизація) — точна відповідь на конкретні питання з PDF-звітів
Збереження знань другого мозку (гібридний) — зберігання та точне відновлення інформації між сесіями
Чотири: Основні висновки: Топ-10 моделей за найвищою успішністю (Найкращий % / Середній %)
Дані оновлено до 7 квітня 2026 року
Найкращий % — це найвища успішність за одну операцію, середній % — це середня успішність за кілька операцій, що краще відображає стабільність
Ось десять найуспішніших моделей
anthropic/claude-opus-4.6 (Anthropic) —— 93,3% / 82,0%
arcee-ai/trinity-large-thinking (Arcee AI) — 91,9% / 91,9%
openai/gpt-5.4 (OpenAI) —— 90,5% / 81,7%
qwen/qwen3.5-27b (Qwen) —— 90,0% / 78,5%
minimax/minimax-m2.7 (MiniMax) — 89,8% / 83,2%
anthropic/claude-haiku-4.5 (Anthropic) —— 89,5% / 78,1%
qwen/qwen3.5-397b-a17b (Qwen) — 89,1% / 80,4%
xiaomi/mimo-v2-flash (Xiaomi) —— 88,8% / 70,2%
qwen/qwen3.6-plus-preview (Qwen) — 88,6% / 84,0%
nvidia/nemotron-3-super-120b-a12b (NVIDIA) —— 88,6% / 75,5%
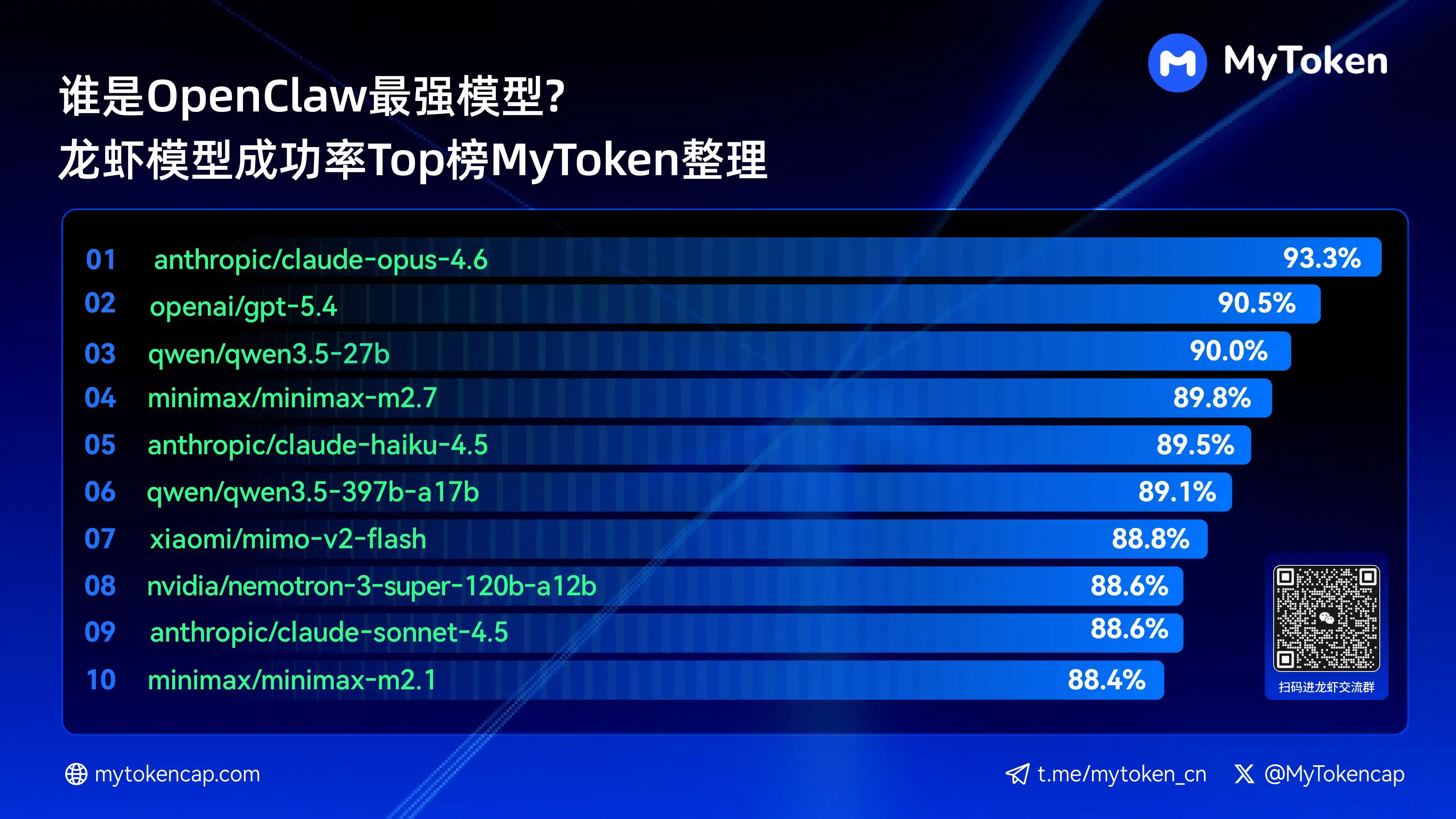
Claude Opus 4.6 зараз лідирує з найвищим рівнем успішності 93,3%, але Trinity від Arcee відзначається високою середньою стабільністю, а серія Qwen також має кілька моделей у топ-10, що свідчить про великий потенціал співвідношення ціни та якості. Успішність — це базовий поріг, а подальше впливатимуть швидкість і витрати.
Цей набір із 23 завдань повністю прозорий, рекомендуємо вам протестувати його в реальних умовах. Більше рейтингів інших моделей — очікуйте майбутньої функції рейтингу агентів від MyToken.
(Дані отримано з публічного бенчмарку OpenClaw від PinchBench, постійно оновлюється.)